Information Retrieval and Web Search まとめ(16): 検索システムの効率性
前回は、多値適合性に基づくランクつき検索評価指標である nDCG と、クリックデータの活用に際しての注意点やテクニックについて解説した。今回は、検索システムの効率性 (efficiency) について議論する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の16日目の記事です。
背景
- クエリ実行時、スコア計算が CPU 全体の数十%を使っている
- 一般的に、レイテンシに関して厳しい制限がある(250ミリ秒とか)
- すべてのクエリですべての文書を網羅的にスコア計算することは許されない
- 検索結果のクオリティは(大きくは)下げずに CPU 使用率を下げる方法をみていく
- 基本的なアイデア:top K に入らない文書のスコア計算を避ける
- 「安全なランキング (safe ranking)」と「安全でないランキング (non-safe ranking)」
- 安全 = top K の文書を正確に返す手法
- 安全ではない = top K の文書に近い K 個の文書が得られれば OK
- 両方の手法を紹介する
効率的なスコア計算とランキング
- 復習:ベクトルとしてのクエリ
- クエリをベクトルとして表現する
- ベクトル空間上の近さで文書をランク付けする
- 近さ = コサイン類似度で定義されるベクトル間の類似度
- 効率的なコサイン類似度でのランキング
- タスク:クエリ-文書間のコサイン類似度が最も大きい K 個の文書を探す
- 1.各々のコサイン類似度を効率的に計算する
- 2.コサイン類似度が最も大きい K 個の文書を選択する
ヒープを使った Top K の選択
- 通常、検索では top K の文書のみが必要で、全文書の順番は不要
- コサイン類似度が 0 ではない文書が
J個あるとするJ個の文書のなかから、大きいものK個を探す
- ヒープ (heap) というデータ構造を使う
- 二分木の一種
- 各ノードの値が、そのノードの子孫よりも大きくなっているという制約がある
- ヒープの構築は
2J回の操作でできる - そのなかから値が大きい
K個のノードを取り出すのは2 log Jステップでできる - たとえば
J = 1M、K = 100だったとき、ソートするコストの約 10%
- コサイン類似度の計算がボトルネック
- 全文書のコサイン類似度を計算せずにできるだろうか?
安全でない top K ランキング
プルーニングによるスコア計算の高速化
- インデックス除去 (index elimination)
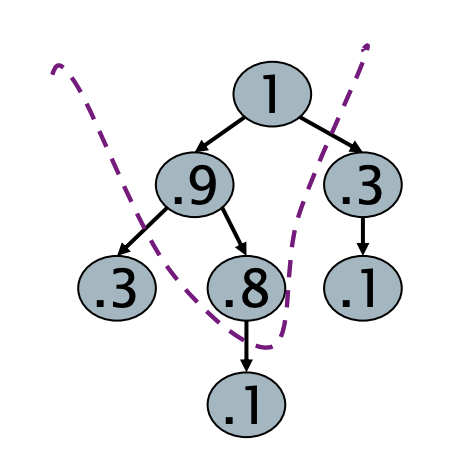
- チャンピオンリスト (champion list)
- 各ターム t のポスティングリストごとに、そのなかで最も重みが大きい r 個のポスティングを事前に計算しておく
- このポスティングを t のチャンピオンリストと呼ぶ
- インデックス構築時に計算される
- クエリ処理ではこのチャンピオンリストにある文書だけをスコア計算する
- 各ターム t のポスティングリストごとに、そのなかで最も重みが大きい r 個のポスティングを事前に計算しておく
静的スコア
- 静的なクオリティスコア
- ポスティングを事前にこの静的スコアでソートしておく
- クエリ処理時にはこの順番で処理し、top K を計算する
- チャンピオンリストの方法と組み合わせられる
クラスタプルーニング
- クラスタプルーニング (cluster pruning) は、文書を事前にクラスタリングしておいてそれを利用する高速化手法
文書を事前にランダムに選択
- これらの文書をリーダー (leader) と呼ぶ
- 他の全ての文書に対して、最も近いリーダーを事前計算しておく
- それらをフォロワー (follower) と呼ぶ
- リーダーはおおよそ
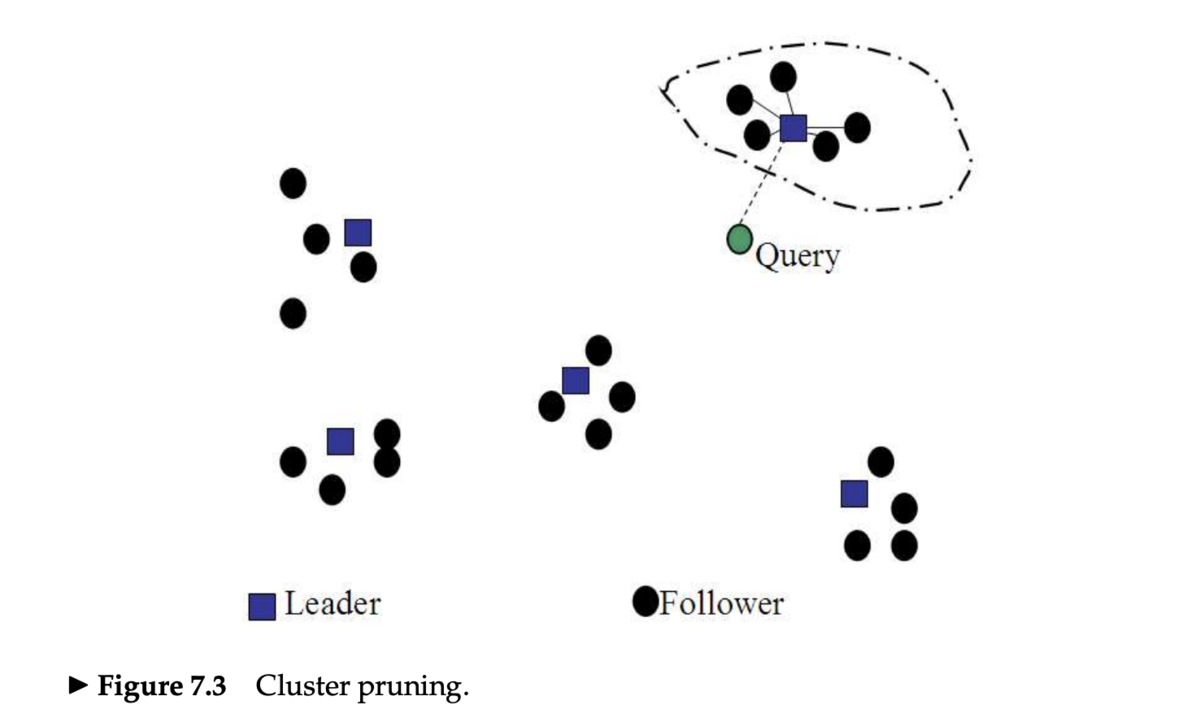
- クエリ処理
- 与えられたクエリに対して、もっとも近いリーダー
Lを見つける LとLのフォロワーの中からもっとも近いK個の文書を探す
- 与えられたクエリに対して、もっとも近いリーダー
- ランダムに選ぶ理由
- 高速
- データの分布を反映したリーダー選択ができる
層化インデックス
- 層化インデックス (tiered indexes) は、転置インデックスを複数の層 (tier) に分けて管理する方法
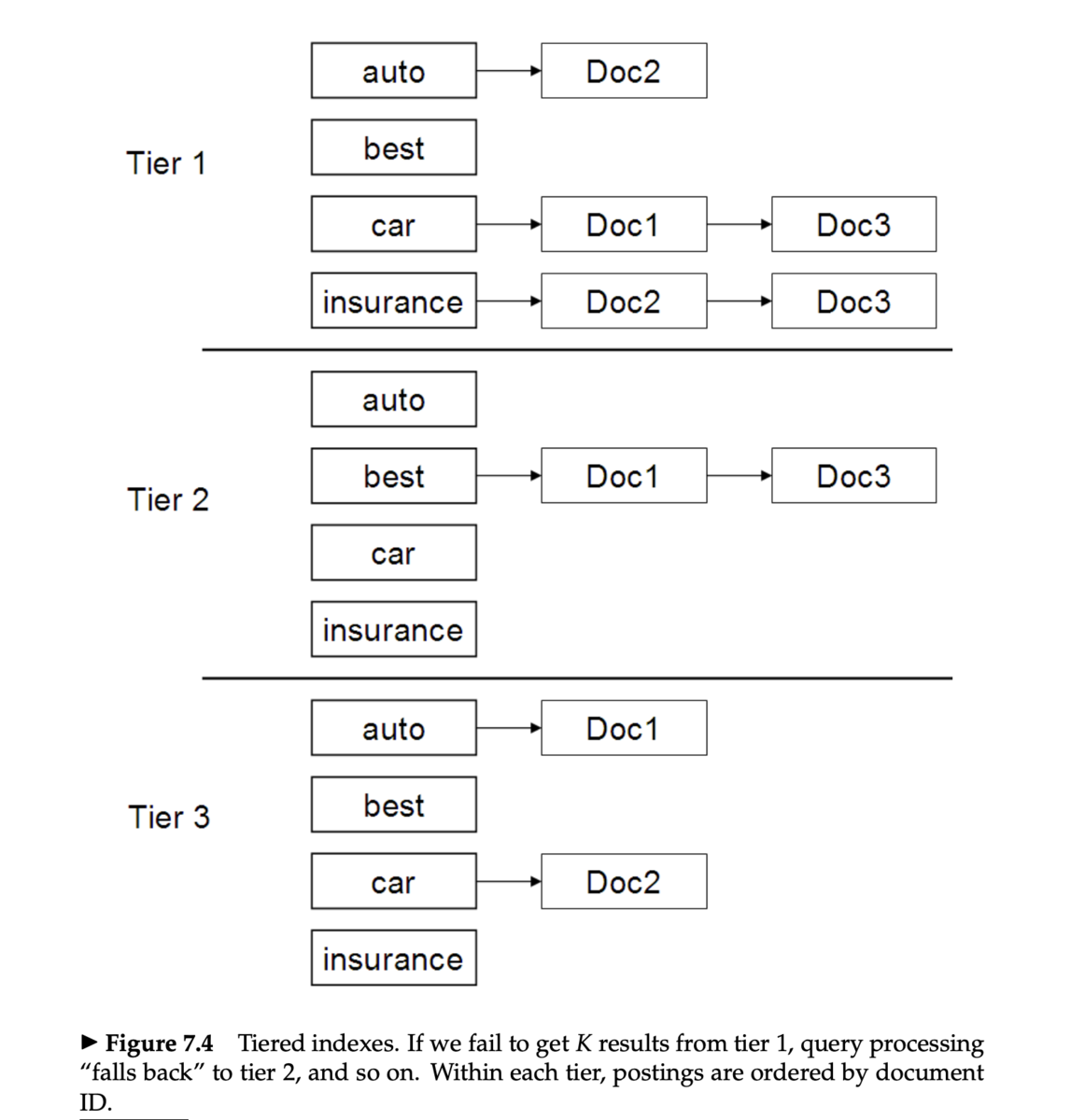
インパクト順ポスティング
- インパクト順ポスティング (impact-ordered postings)
が大きい文書のみスコア計算したい
- 早期終了 (early termination)
- 固定された数 r だけ文書を見たら終了、もしくは
- それらの和集合のみスコア計算する
- 固定された数 r だけ文書を見たら終了、もしくは
- IDF-ordered terms
- IDF の降順でタームを見ていく
- IDF が高いタームはスコアへの寄与も大きい
- 各クエリタームのスコアへの寄与が相対的に変わらなくなったら終了
- IDF の降順でタームを見ていく
安全な top K ランキング:WAND
- 安全なランキング (safe ranking)
- スコアが top K の文書を正確に返す手法
- スコアはコサイン類似度に限らない
- 一部の文書のスコア計算をしない
- プルーニング (pruning) = 枝刈りを行う
WAND
- DAAT スコアリング手法の一つ
- クエリ処理の実行中、スコアの閾値 (threshold) を管理する
- 閾値は K 番目に高いスコア
- スコアがこの閾値より高くならないことがわかった文書は枝刈り (prune) する
- 枝刈りされなかった文書のみスコアを計算する
- [Broder et al. Efficient Query Evaluation using a Two-Level Retrieval Process.]
参考:Research Paper Introduction in IR Reading 2020 Fall
WAND のインデックス構造
- ポスティングは docID によってソートされている
- 普通の転置インデックスでも仮定されている
- クエリ処理の実行中、各クエリタームのポスティングリストごとに、一つのポインタ ("finger") をもつ
- それぞれのポインタは右にのみ(つまり docID が大きくなる方向にのみ)動く
- 不変条件
- 各ポインタより左にある docID はすでに「処理された」ことを意味する
- 枝刈りされたか、もしくはスコアが計算されたか
- 各ポインタより左にある docID はすでに「処理された」ことを意味する
上限
- 各クエリターム t ごとに、常に上限 (upper bound)
を保持する
- ポインタより右にある文書の、スコアへの貢献 (contribution)
の最大
- ポインタが右に動くことで、
- ポインタより右にある文書の、スコアへの貢献 (contribution)
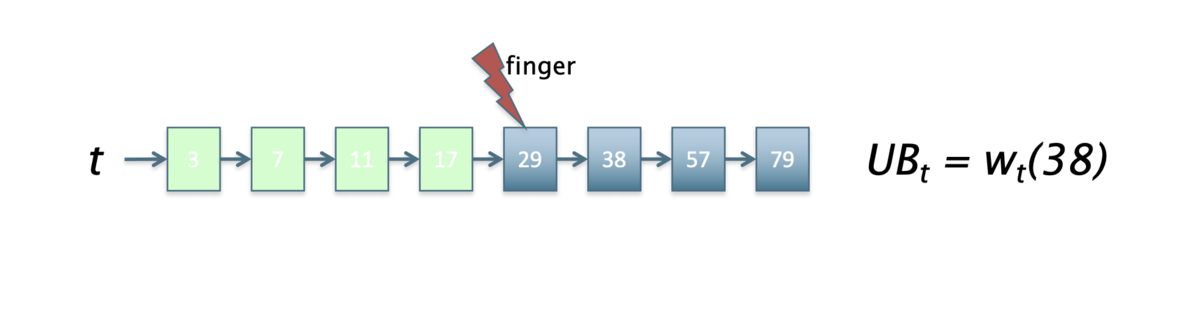
WAND によるクエリ処理
- クエリ "catcher in the rye" を処理しているある時点での各ポインタと上限
- クエリタームはポインタの位置でソートされている
- 現在の閾値(いままで計算したなかで K 番目のスコア)は
6.8

- 上から順番に上限
6.8を超えるクエリタームを探す- この場合は "in"
- そのタームをピボット (pivot) と呼ぶ
- ピボットのポインタが指している docID までは安全にスキップできる

- もしピボット位置の文書が閾値を超えそうなら、そのコサイン類似度全体を計算する
- そうでない場合、いくつかのポインタがそれより右にある
- さらにピボットの再計算を行う(繰り返し)
WAND のまとめ
- 90% 以上のスコア計算を削減できることが実験で確かめられている
- より長いクエリではそれ以上
- コサイン類似度によるスコアリングに限らない
- タームに対してスコアが加法的 (additive) であればよい
- WAND とその亜種は安全なランキングである