Information Retrieval and Web Search まとめ(19): 分散表現
前回は決定木によるテキスト分類について説明した。今回は、情報検索での分散表現の利用について解説する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の19日目の記事です。
単語の表現
- ユーザの検索意図をどうやって頑健にマッチするか?
- クエリを(字面通りではなく)理解 (understand) したい
- クエリが
Dell notebook battery sizeだったとき、Dell laptop battery capacityに言及している文書にマッチさせたい - クエリが
Seattle motelだったとき、Seattle hotelを含む文書にもマッチさせたい
- クエリが
- キーワードベースの情報検索システムでは難しい
- スペル訂正、ステミング、小文字への正規化 (case folding) 役立つときもあるが限定的
- クエリを(字面通りではなく)理解 (understand) したい
- クエリ拡張 (query expansion)
- 単語の類似度を使うことができる
- 手で構築されたシソーラス(類語辞書)
- 単語類似度の尺度
- 大規模なコレクションから計算されたもの
- Web などのクエリログから計算されたもの
- 単語の類似度を使うことができる
- 文書拡張 (document expansion)
- Web ページにおけるアンカーテキスト (anchor text) でシノニムを解決できるかもしれない
- Web ページによっては使えないこともあるし、ハイパーリンクのないコレクションでは不可能
- Web ページにおけるアンカーテキスト (anchor text) でシノニムを解決できるかもしれない
検索ログによるクエリ拡張
- 文脈のないクエリ拡張は失敗する
wet ground~wet earthなので、ground-->earthと拡張すると...ground coffee(挽いたコーヒー豆) !=earth coffee
- 同じユーザの context-specific なクエリ書き換えのログから学習することはできる
Hinton word vectorHinton word embedding- この文脈では
vector~embedding
シソーラスの自動生成
- 文書のコレクションを解析することでシソーラスを自動生成することができる
- シンプルなものだと、タームの共起行列から計算する方法がある

タームの関係性の表現
- 標準的な符号化方法だと、各タームはそれぞれ1つの次元に対応する
- 異なるタームは関係がないものとして扱われる
- たとえば、
hotelを 3 つ含む文書と、motelを 1 つ含む文書があったとして、それらの文書ベクトルは直交するので内積をとっても 0 になってしまう
- Query translation model [Berger and Lafferty (1999)]
- 基本的な情報検索のスコアリングは
- スコアリングを
と修正して、W のパラメータを学習する
- しかし、その行列 W が疎であるという問題は解決しない(W の次元は
以上)
- 基本的な情報検索のスコアリングは
- 解決策:低次元密ベクトル
- アイデア:固定長の低次元密ベクトルに、最も重要な情報を詰め込む
- 通常、 25 - 1000 次元
- 高次元の疎なカウントベクトルから、低次元の「単語埋め込み (word embedding)」へと変換する
- 古典的な方法:潜在意味インデキシング/潜在意味解析 (latent semantic indexing/analysis)
ニューラル埋め込み
- 単語を密ベクトルで表現する
- そのベクトルは、その文脈で登場する他の単語を予測できるようなものが選ばれる
- 他の単語もベクトルで表現されている
ニューラルネットワークと単語埋め込み
基本的なアイデア
- 中央の単語 (center word)
から、周辺の単語 (context word) を予測するモデルを定義する
- この上に損失関数を定義し、大規模なコーパスからモデルを学習する
- t の位置をずらしながら学習していく
- この損失関数を最小化するような単語のベクトル表現が学習される
低次元の単語ベクトルの学習
- 逆伝搬誤差 (back-propagating error) によってベクトル表現を学習 [Rumelhart et al., 1986]
- 古い方法
- ニューラル確率言語モデル [Bengio et al., 2003]
- NLP from Scratch [Collobert & Weston, 2008]
- 非線形かつ遅い
- Word2vec(よりシンプルで速いモデル) [Mikolov et al. 2013]
- バイリニア (bilinear) で速い
- GloVe(matrix factorization と接続) [Pennington, Socher, and Manning 2014]
- バイリニア (bilinear) で速い
- ELMo、ULMfit、BERT(トークンごとのベクトル表現、Deep contextual word representation)
- 現在の stage of the art
Word2vec
- Word2vec は、ある単語 (center word) とその周辺の単語 (context words) を予測するモデル
- 2つのアルゴリズムがある
- Skip-gram (SG)
- (ポジションに対して独立な)ターゲットの単語から周辺の単語を予測する
- Continuous Bag of Words (CBOW)
- bag-of-words の文脈から、ターゲットの単語を予測する
- Skip-gram (SG)
- 訓練方法
- 階層的ソフトマックス (hierarchical softmax)
- ネガティブサンプリング
- ナイーブソフトマックス (naive softmax)
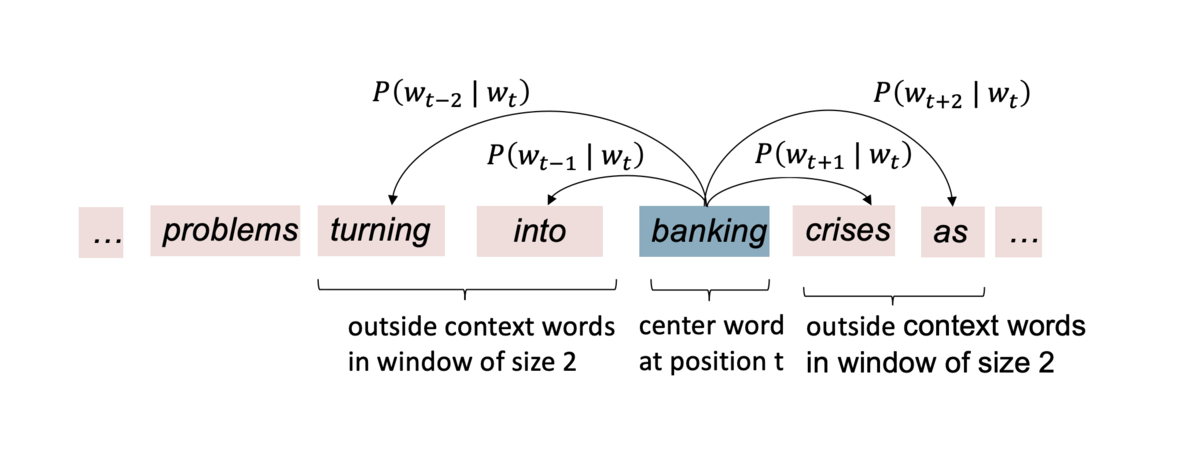
Skip-gram
- Skip-gram で
を計算する例
bankingが center word- ウィンドウサイズは 2
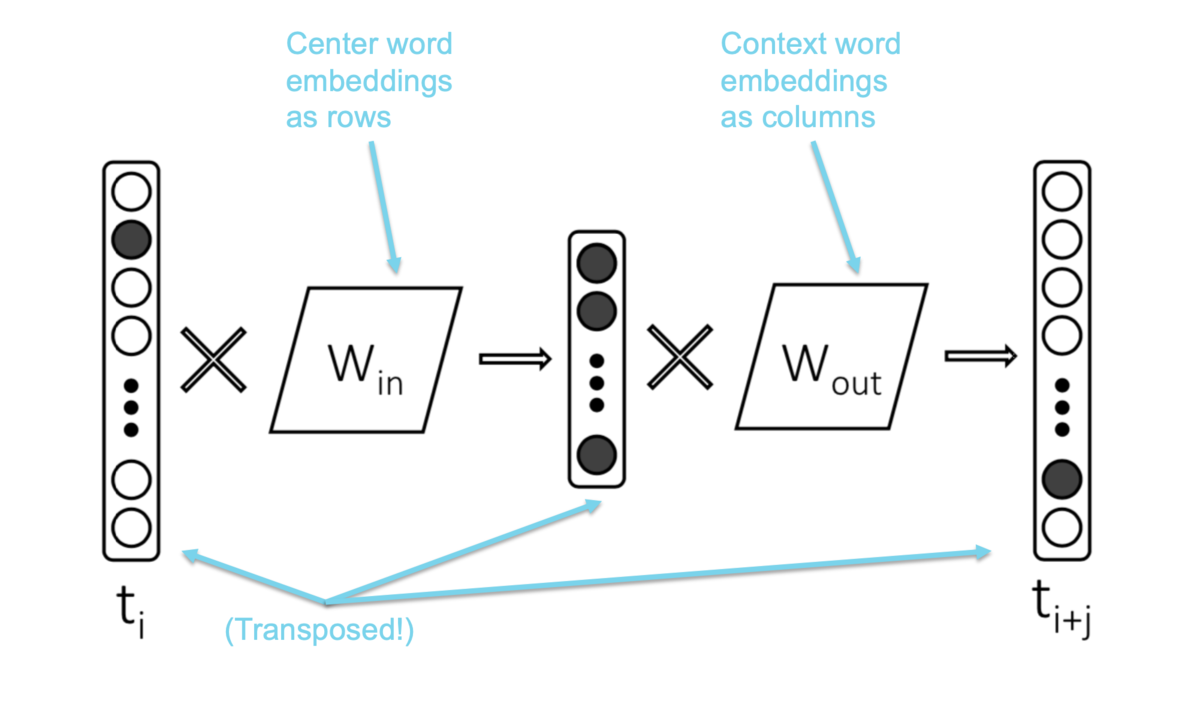
- 2つのパラメータ行列
は center word の埋め込みとなる(行が単語を表す)
は context word の埋め込みとなる(列が単語を表す)
Word2vec の線形性
- Word2vec による単語のベクトル表現は、類似度と類似度の次元を、とてもうまくエンコードする
構文的な関係性
意味的な関係性 [Semeval 2012 task 2]
情報検索への応用
- 分散表現の情報検索への応用は、まだ始まったばかり
- Google RankBrain
- Google Turning Its Lucrative Web Search Over to AI Machines - Bloomberg
- 検索結果のリランキングシステム
- 3番目に大きいランキングシグナル
- SIGIR Neu-IR workshop (2016-)
- Google RankBrain
ニューラルネットによるリランキング
- ニューラルネットを教師ありのリランカーとして使う
- クエリと文書それぞれの埋め込みネットワークがあるとする
- また、クエリと文書とその適合度の組
(q, d, rel)のデータがあるとする - ニューラルネットワークを教師あり学習し、
(q, d)の組の適合度を予測する
Dual Embedding Space Model (DESM)
- Nalisnick, Mitra, Craswell & Caruana. 2016. Improving Document Ranking with Dual Word Embeddings. WWW 2016 Companion.
- Mitra, Nalisnick, Craswell & Caruana. 2016. A Dual Embedding Space Model for Document Ranking.
- BM25 の "aboutness" のアイデアから作られたモデル
- aboutness を表すのは、タームの繰り返しだけではない
- クエリタームと、文書に出現するすべてのタームとの関連性 (relationship) も aboutness を表す


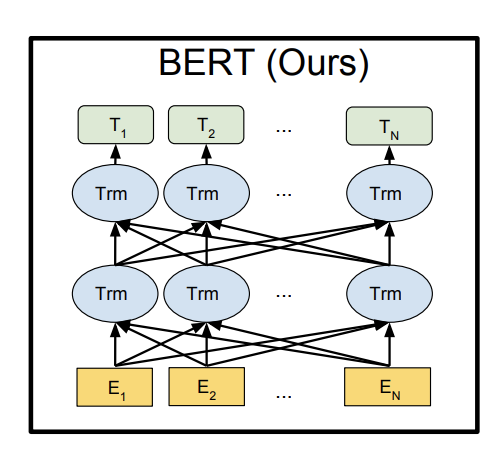
BERT
- BERT: Devlin, Chang, Lee, Toutanova (2018)
- Transformer ベースの DNN
- トークンごとの表現を(コンテキストありで)出力する
- クエリや文書の表現も同様に作れる
- もしくはクエリと文書を同時に埋め込み、適合スコアを求める
- 非常に効果的