Information Retrieval and Web Search まとめ(17): テキスト分類(1)
前回は、様々なプルーニングアルゴリズムによって検索システムを高速化する方法について説明した。今回から、文書のテキスト分類について解説していく。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の17日目の記事です。
テキスト分類の概要
継続クエリ
- ここまでは、主にアドホック検索を対象としていた
- ユーザは一過性の情報ニーズをもっていて、ユーザが検索システムにクエリを入力する、というケース
- しかし、多くのユーザはもっと継続的な (ongoing) 情報ニーズも持っている
- 毎朝ユーザがクエリを発行する代わりに、これを自動化することでユーザをサポートできる
- そのクエリと適合する文書が新しく追加されたら、これを通知するようにできる
- このようなクエリを継続クエリ (standing query) と呼ぶ
- 専門家 ("information proofessinals") によって長らく使われてきた
- 例:Google Alerts
- 継続クエリは、(手で書かれた)テキスト分類器である
- 情報ニーズに適合する文書 (relevant) か、適合しない文書 (not relevant) かを分類 (classification/categorization) している
- 他にも、スパムフィルタなどのテキスト分類タスクがある
テキスト分類タスク
- 入力 (given)
- 文書 d の表現(BOW など)
- 決められたクラス集合
- 出力 (determine)
- d のカテゴリ
は分類関数 (classification function)
- この分類関数(分類器 (classifier))を構築したい
- d のカテゴリ
テキスト分類の方法
- マニュアル分類
- 手で作られたルールベース分類器
- 広く使われているが、メンテナンスが大変
- 教師あり学習 (supervised learning)
教師あり学習
- 入力 (given)
- 文書 d の表現
- 決められたクラス集合
- 訓練セット D
- 訓練セット内の文書には C のラベルが1つついている
- 出力 (determine)
- テスト文書 d に対して、カテゴリ
を割り当てる
- 分類器
を学習させるアルゴリズムが必要
- 分類器
- テスト文書 d に対して、カテゴリ
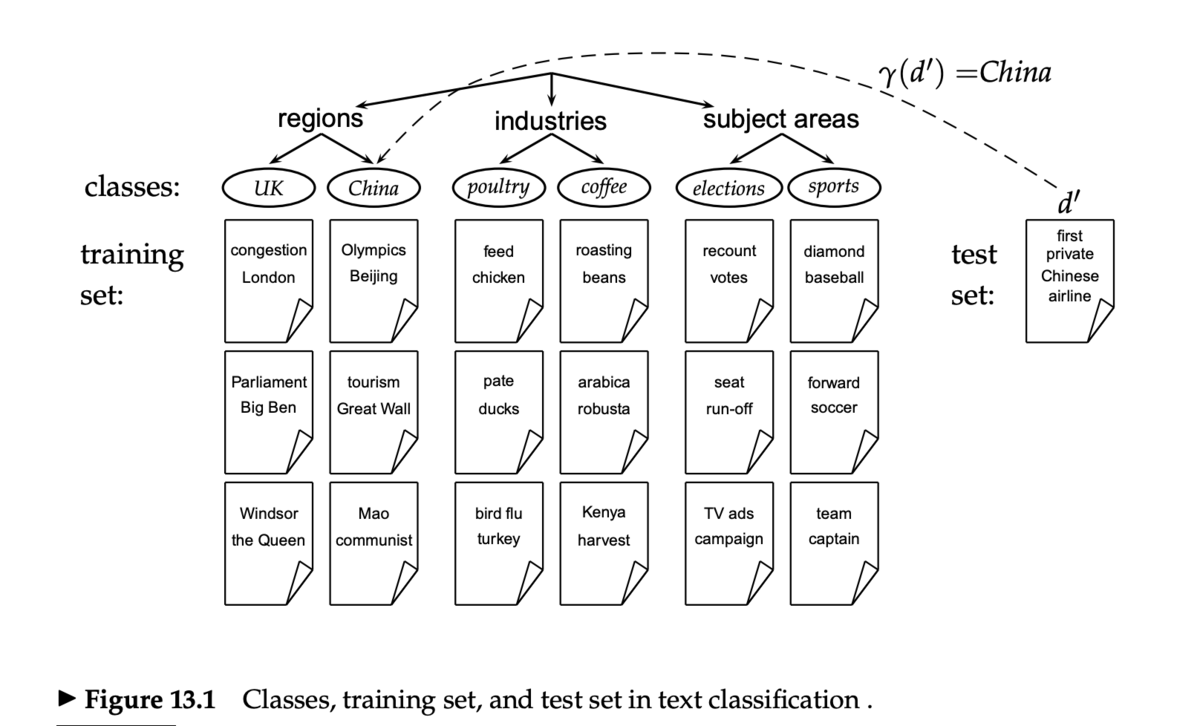
- 教師あり学習の手法
特徴量
- 教師あり学習の分類器はさまざまな特徴量を扱える
- URL、メールアドレス、辞書など
- テキストに含まれる単語の特徴量を使う
- BOW (bag of words)
特徴選択
- コレクションには大量のユニークな単語がある(1万〜100万)
- 特徴量(の次元)を減らすことで、学習時間を短くし、モデルを小さく速くし、過学習 (overfitting) を避けられる
- モデルによってはそもそも100万個の特徴量を扱えないものもある
- 特徴選択 (feature selection):単語の頻度を使って特徴量となる単語を選択できる
- 単純に common な単語だけを使うなど
- 他にもカイ二乗法などのスマートな方法もある
評価指標
- 精度 (precision)
- 再現率 (recall)
- F1スコア (F1 score)
- 正解率 (classification accuracy)
ナイーブベイズ
- Ref. IIR chapter 13
- SpamAssassin などに応用されている
- 学習も予測も非常に速い
- モデルのストレージ上のサイズが小さい
- 特徴量(単語)がそれぞれ同程度に重要であるようなコレクションには非常に適している
- ノイズのような特徴量に対してもロバスト
- 概念ドリフト (concept drift)(時間経過でクラスの意味が変化すること)に対してもロバスト
- KDD CUP 97 で1位と2位になっている
- テキスト分類におけるよいベースライン(ベストではないが)
WebKB 実験
- [Craven et al. 1998]
- Web ページのクラス分類
- CMU のコンピュータサイエンスの学部 Web サイトをクロールした ~5000 文書からなるデータセット
- クラスは
Student,Faculty,Person,Project,Course,Departmentの6つ - 各 Web ページは手でクラスがラベル付けされている
- ナイーブベイズで学習・分類

講義資料
参考資料
- IIR chapter 13
- IIR chapter 14
- Reuters-21578
- Machine learning in automated text categorization (Sebastiani 2002)
- A re-examination of text categorization methods (Yang et al. 1999)
- A Comparison of event models for naive Bayes text classification (McCallum et al. 1998)
- Tackling the poor assumptions of Naive Bayes classifier (Rennie et al. 2003)
- Evaluating and optimizing autonomous text classification systems (Lewis 1995)
- Tom Mitchell. Machine Learning. McGraw-Hill, 1997.
- Trevor Hastie, Robert Tibshirani, Jerome Friedman. Elements of Statistical Learning: Data Mining, Inference, and Prediction. Springer-Verlag, New York, 2001.
- Open Calais
- Weka