Information Retrieval and Web Search まとめ(20): ランク学習
前回は Word2vec, BERT などの単語埋め込み手法と、それらの情報検索への応用について説明した。今回は、ランク学習について紹介する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の20日目の記事です。
情報検索のための機械学習
- これまでに検索における文書のランキング手法をいくつか見てきた
- コサイン類似度、BM25...
- また、教師ありの機械学習を使った文書分類(クラス分類)の方法も見てきた
- ロッキオの方法、kNN、決定木...
- 文書のランク付けにも機械学習を使えないか?
- "machine-learned releance", "learning to rank" として知られている
歴史
- 検索ランキングのための機械学習はアクティブに研究されてきた
- また、この10年で主要な検索エンジンにデプロイされている
- 過去の研究
- Wong, S.K. et al. 1988. Linear structure in information retrieval. SIGIR 1988.
- Fuhr, N. 1992. Probabilistic methods in information retrieval. Computer Journal.
- Gey, F. C. 1994. Inferring probability of relevance using the method of logistic regression. SIGIR 1994.
- Herbrich, R. et al. 2000. Large Margin Rank Boundaries for Ordinal Regression. Advances in Large Margin Classifiers.
- 初期の研究はそれほどうまくいっていなかった
- 訓練データが少なかった
- 特に実世界のデータ
- クエリログ、適合性判定のデータを集めるのは大変
- 機械学習手法もまだ発展していなかった
- 情報検索の問題への適用が不十分だった
- 特徴量が十分ではなかった
- 訓練データが少なかった
機械学習の必要性
- 現代的な(Web の)システムは大量の特徴量を扱う
- ターム頻度などの古典的な特徴量だけではなく、ページ中の画像の数、リンクの数、PageRank、URL、更新日時、ページの表示速度...
- Google は 2008 年には 200 以上の特徴量(シグナル)を使っており、今日では 500 以上になっているだろう
ランク学習
- クラス分類はアドホック検索への適切なアプローチではない
- ランキング問題では、文書が他の文書に対してよいかどうかを議論する
- よさの絶対的な尺度は必要ない
- ランク学習 (learning to rank)
- 以下のような適合性のカテゴリの集合 C が存在すると仮定する
- C のすべてのカテゴリ
には全順序がついている (totally ordered)
- (これは順序付き回帰の問題設定と同じ)
- C のすべてのカテゴリ
- 以下のような文書とクエリのペア
(d, q)からなる訓練データを仮定する(d, q)は特徴量ベクトルで表され、それに適合ランキング
- 以下のような適合性のカテゴリの集合 C が存在すると仮定する
検索ランキングのためのアルゴリズム
- SVM (Vapnik 1995) のランキングへの適用:Ranking SVM (Joachims 2002)
- ニューラルネット:RankNet (Burges et al. 2006)
- Tree Ensemble
- ランダムフォレスト (Breiman and Schapire 2001)
- Boosted Decision Tree
- 2010 年の Yahoo! Learning to Rank Challenge ではすべてのトップチームが Tree Ensemle の手法の組み合わせを使った
Yahoo! Learning to Rank Challenge
- [Chapelle and Chang, 2011]
- 以下のような Yahoo! Webscope のデータセットを使って行われた
- クエリ数:36,251
- 文書数:883k
- 特徴量:700種類
- ランキング:5段階
- 優勝したモデル (Burges et al. 2011) は 12 のモデルの線形結合だった:
- 8 つの Tree Ensemble (LambdaMART)
- 2 つの LambdaRank ニューラルネットワーク
- 2 つのロジステック回帰
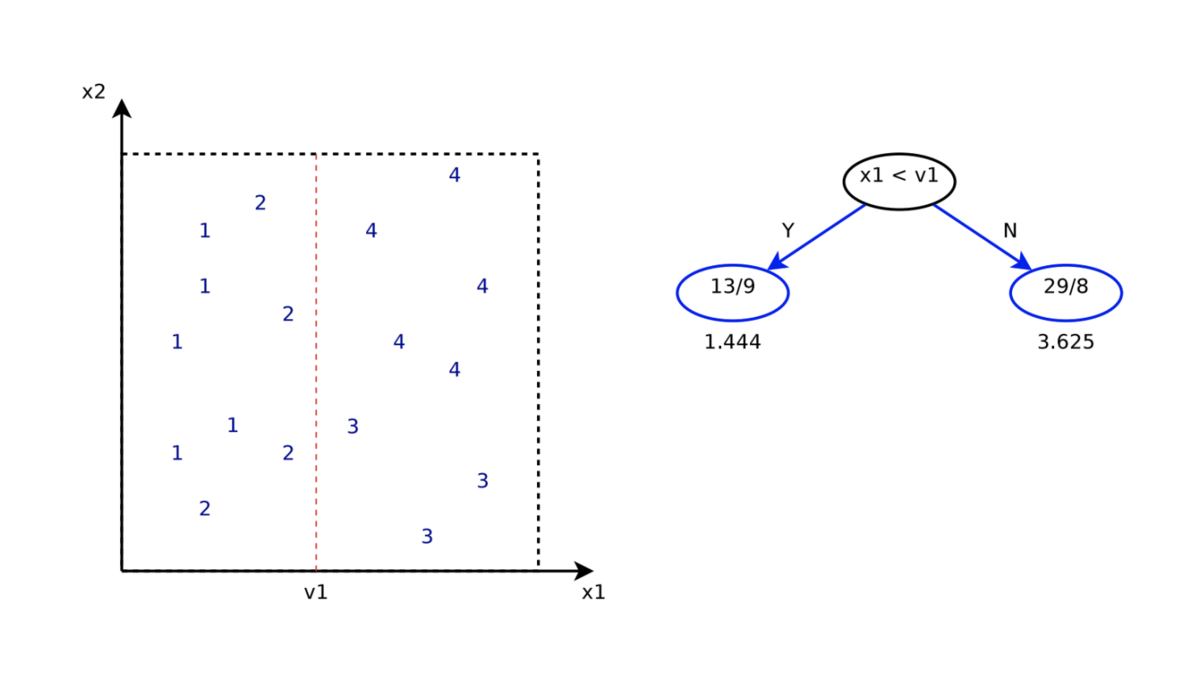
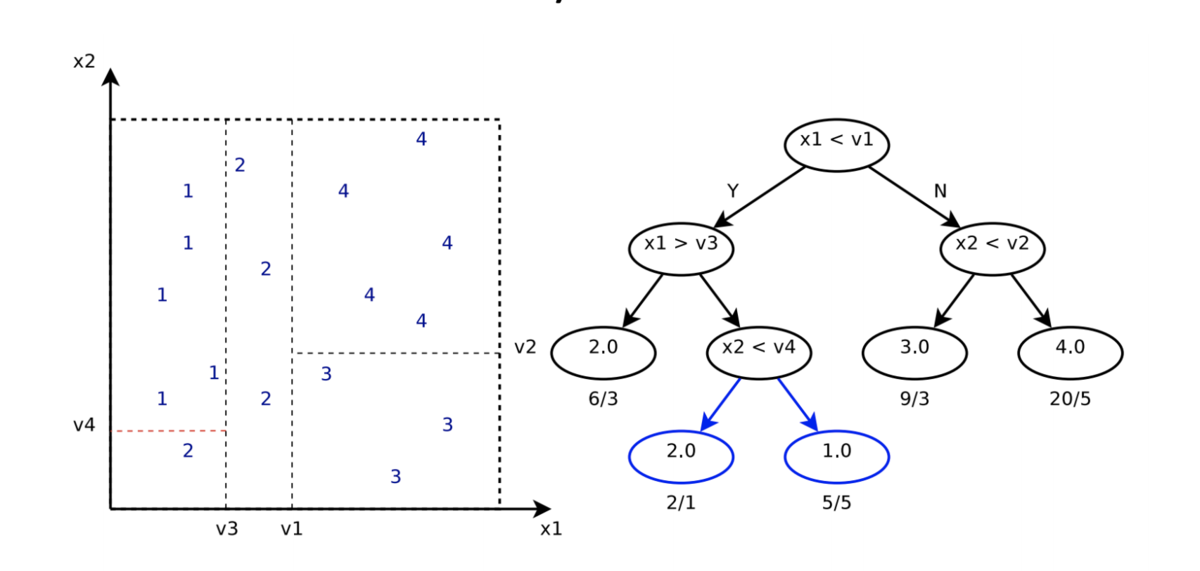
回帰木
- 回帰木 (regression tree) は、実数を予測できる決定木
- 葉ノードには、その葉ノードに含まれるすべてのサンプルの平均値 (mean) を保持する
- 分割規準:標準偏差 (standard deviation; SD) の最小化
- 学習時には、分割する変数
と、その変数上での分割点
を探索する
- それらは予測誤差
を最小化するように選ぶ
- それらは予測誤差
勾配ブースティング
ブースティングのモチベーション
- Q:「独立な弱い (weak) 分類器を組み合わせて、高い精度の分類器を構築できるか?」
- 古典的なアプローチ: AdaBoost
- すべての木の重み付きの投票で分類する
ブースティングによる関数の推定
- ほしいもの:損失関数
の期待値を最小化する、以下のような関数
- ブースティングでは、
を以下のような形で近似する
は
でパラメータ化された関数
は重み係数
- 関数のパラメータはイテレーションにより訓練データにフィットさせる
勾配ブースティングの学習
- 勾配ブースティング (gradient boosting) は、任意の微分可能な損失関数に対して関数
を推定できる
- 関数
- ただし
は「疑似残差 (pseudo-residual)」であり
Gradient Boosted Regression Tree (GBRT)
- Gradient Boosted Regression Tree (GBRT) は、この勾配ブースティングのアプローチを回帰木 (regression tree) に適用する
- それぞれの回帰木は通常 1-8 の分割しか持たない
- GBRT の学習
- 最初に、すべての
- 訓練データの誤差を最小化する定数
- 木のルートノードの値
を探索する
- 最小二乗法によりルートノードを分割する
- さらに誤差を最小化する木を追加する
- 最初に、すべての
MART
- Multiple Additive Regression Trees (MART) [Friedman 1999]

RankNet
- RankNet [Burges et al. 2005] はニューラルネットによる ranker
- モデルパラメータ w に対して微分可能な関数
をスコア関数とする
が
- クエリ q に対して、各文書の組
に対するランキングのクラスの確率
を学習する
が
よりランキングが上である確率
はシグモイド関数の傾きを決めるパラメータ
- 損失関数 C はクロスエントロピー損失
は実際の確率(各カテゴリに対して0/1で与えられる適合性の判定)
- ただし、
RankNet の Lambda
- これを使って損失関数の
に対する微分は以下のようにできる
- この式を使って重み
は、文書
- クエリ-文書ベクトル
の総和
を定義する
- この
- (a) は最適なランキング
- (b) は 10 のペアワイズ誤差をもつランキング
- (c) は 8 のペアワイズ誤差をもつ
- 青の矢印は最後の文書の勾配
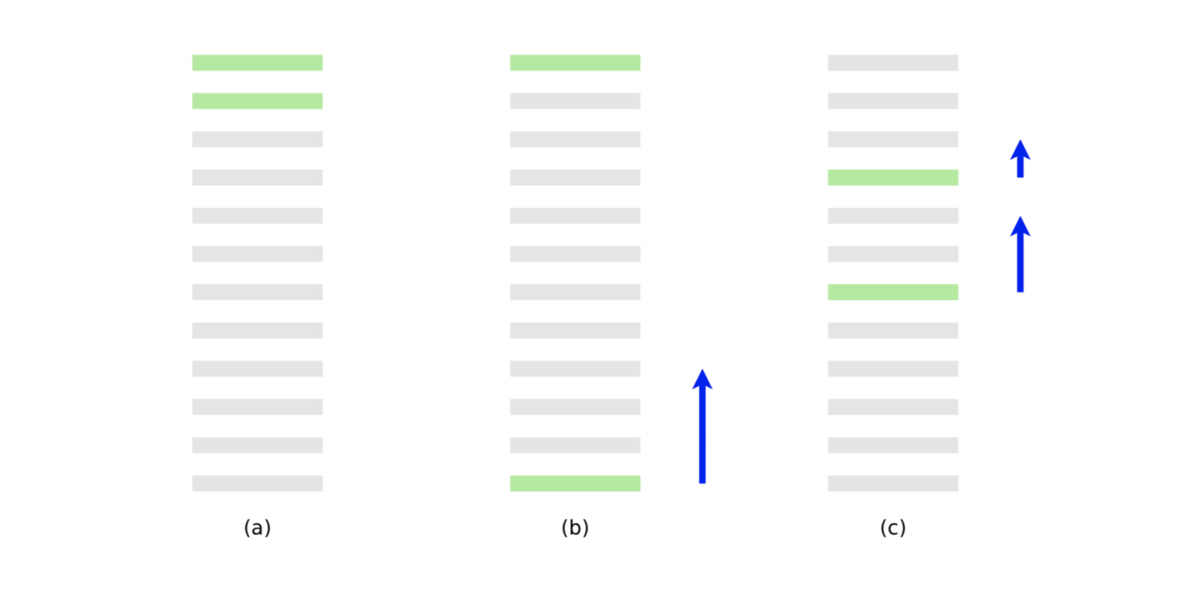
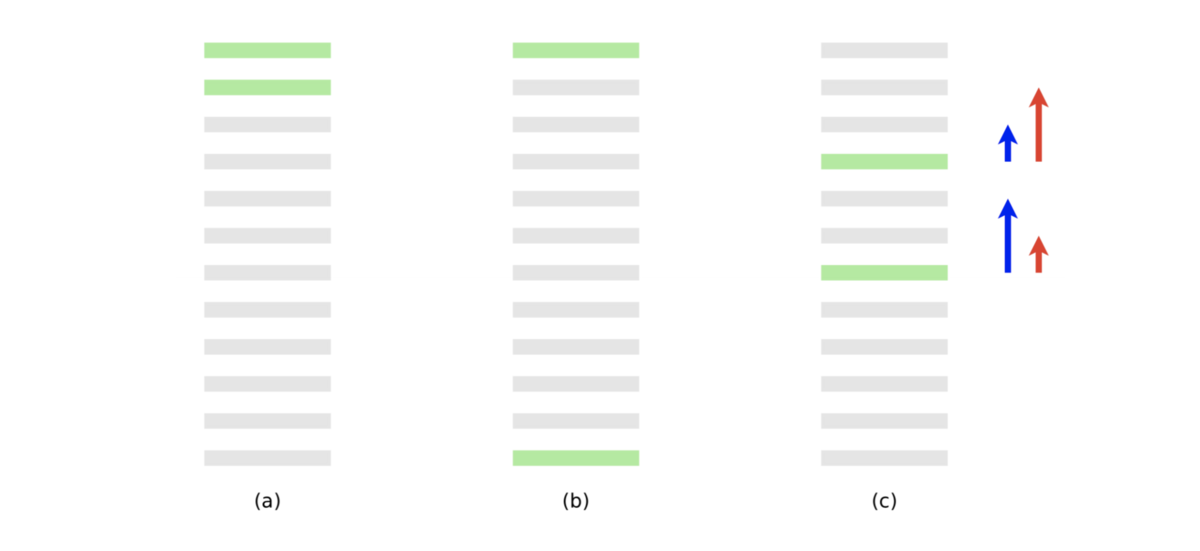
- 青の矢印でペアワイズ誤差は減り、2値の適合性評価指標は改善する
- しかし、NDCG や ERR のような、上位により大きい重みをつける指標では、以下の赤の矢印のような勾配のほうが望ましい
LambdaRank
- LambdaRank [Burges et al. 2006]
- RankNet のようなペアワイズ誤差ではなく、NDCG の効果を入れる
- アイデア:
を
倍する
は、文書
(NDCG の変化)を使って
を以下のようにする
- Burges et al. は、この変更によって NDCG に対して十分に最適化できることを示した
LambdaMART
- LambdaRank は勾配をモデル化している
- MART は勾配(勾配ブースティング)によって学習できる
- この2つを組み合わせたのが LambdaMART [Burges 2010]
- MART に LambdaRank の勾配を入れた

- 前述の通り、Yahoo! Learning to Rank Challenge で LambdaMART (と他のモデルとの線形結合)を使ったチームが優勝 [Burges et al. 2011]
- 結合されたモデルと、それぞれの単体でのスコアは以下の通り
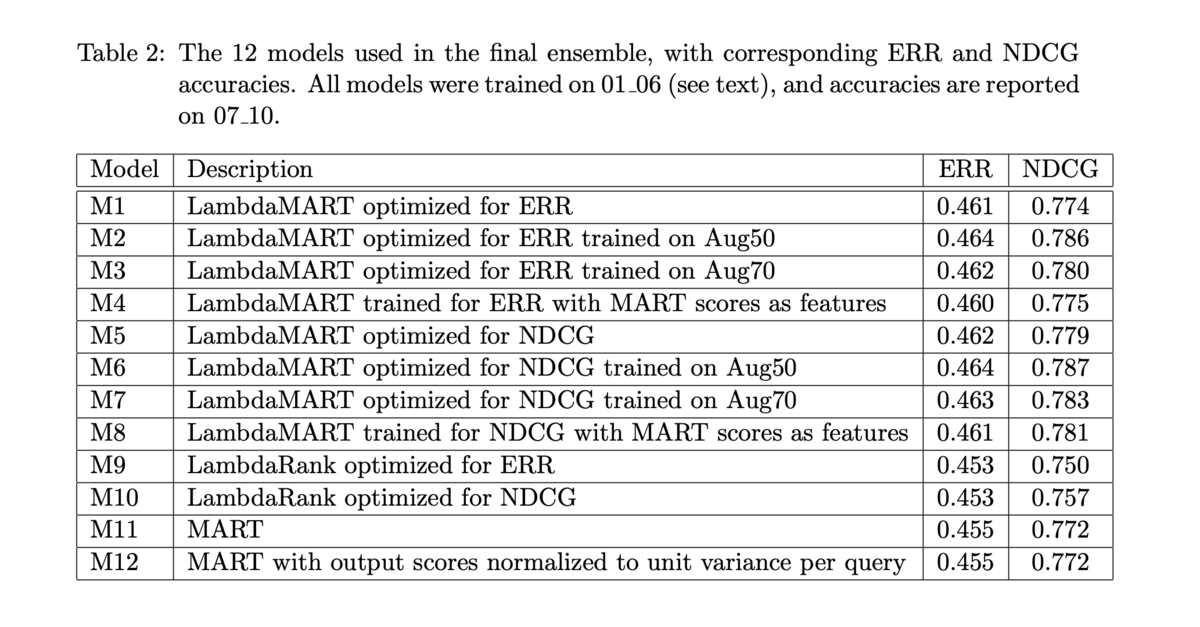
- 多くのモデルを組み合わせなくても十分に高い性能を示す
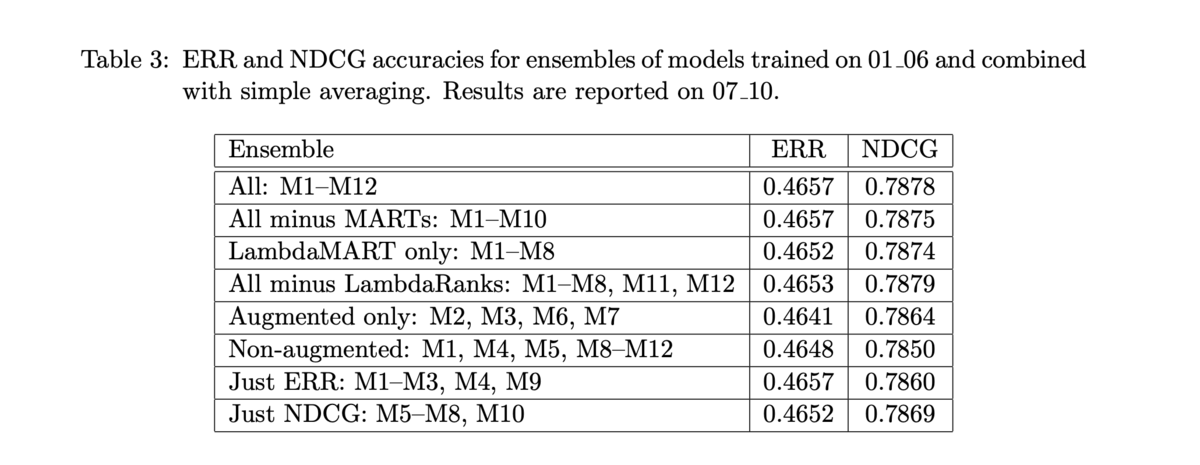
- 他のチームも僅差
- ペアワイズの Logistic Rank もいい結果を残している
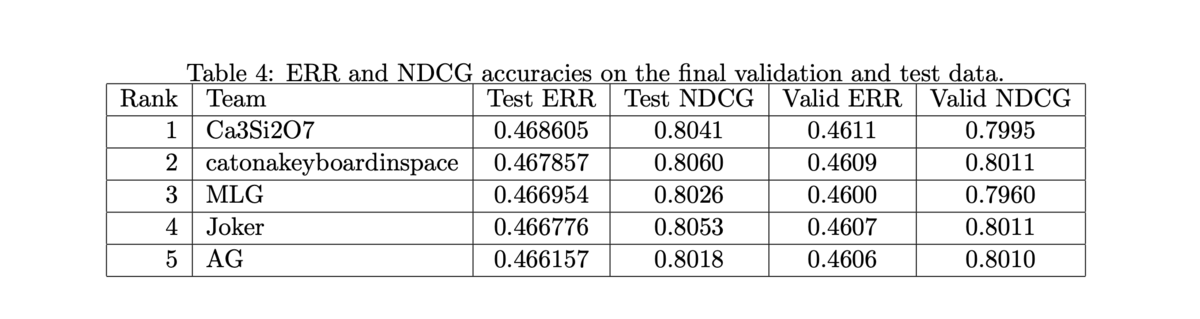
講義資料
参考資料
- IIR sections 6.1.2-6.1.3
- IIR section 15.4
- Discriminative models for information retrieval (Nallapati 2004)
- Adapting ranking SVM to document retrieval (Cao et al. 2006)
- A support vector method for optimizing average precision (Yue et al. 2007)
- LETOR benchmark datasets
- C. J. C. Burges. From RankNet to LambdaRank to LambdaMART: An Overview. Microsoft TR 2010.
- O. Chapelle and Y. Chang. Yahoo! Learning to Rank Challenge Overview. JMLR Proceedings 2011.
- Why is machine learning used heavily for Google's ad ranking and less for their search ranking? What led to this difference? - Quora
- Raw example of xgboost for ranking with LambdaMART
- Statistical Consulting: Multiple Additive Regression Trees (MART)