Information Retrieval and Web Search まとめ(24): 質問応答
前回は、shingle とスケッチを利用した重複検知について説明した。今回は、Web における質問応答を扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の24日目の記事です。
情報検索と質問応答
- 情報検索 (information retrieval) という名前は標準になっているが、実際に行われているのは文書検索 (document retrieval) であることが多い
- それ以上のことはユーザが自身に任されている
- 2025 年のウェブ検索はどうなっているだろう?
- 検索ボックスにキーワードを入力している?
- セマンティックウェブを使っている?
- 自然言語でコンピュータに質問している?
- ソーシャル検索、もしくは人力の (human powered) 検索を使っている?
Google 検索の歴史
- Pigeon アップデート (July 2014)
- ランキングシグナルとして距離や位置情報をより重視するようになった
- Mobilegeddon (Apr 21, 2015)
- モバイル親和性 (mobile friendliness) が主要なランキングシグナルに組みこまれた
- App Indexing (Android, iOS support May 2015)
- 検索結果からアプリに遷移できるようになった
- Mobile-friendly 2 (May 12, 2016)
- 約半数の検索がモバイル由来になった
- Fred (1Q 2017)
- スパムサイト (spammy, clickbaity, fake) を下げるような様々な変更が入った
- 検索結果ページのスニペットがより長くなった (Nov 2017)
- Mobile-first Index (Mar 2018)
- デスクトップ版ではなくモバイル版のページをインデックスするようになった
- 検索結果ページのスニペットの長さが元に戻った (May 2018)
- Medic アップデート
- ページの専門性、権威性、信頼性をより重視するようになった
- ダイエットや栄養、医療品に関するサイトでランキングに大きな変化があった
- コアアルゴリズムアップデート (Mar 2019)
- "Medic 2" 的なアップデートがされた
ナレッジベースを使った検索
- 古典的なテキスト検索ではなく、構造化されているナレッジベース (knowledge base) を使ってグラフ検索を行う
- Google Knowledge Graph
- Facebook Graph Search
- Bing’s Satori
- Wolfram Alpha
- Web ページに埋め込まれている半構造化データを使ったアプリケーションも増えている
Web 検索における最近の課題
- モバイル検索の増加
- 情報の質
- 情報源 (information provenance) や情報の信頼性 (information reliability) は Web においてずっと懸念されてきたが、近年、「フェイクの (fake)」情報が拡散されるようになっている
知的エージェントに向けて
- 2つのゴール
- 文字列を使わない (things, not string)
- 検索ではなく推論 (inference)
質問応答
質問応答のパラダイム
- テキストベースのアプローチ
- TREC QA, IBM Watson, DrQA
- 構造化されたナレッジベースを使ったアプローチ
- Apple Siri, Wolfram Alpha, Facebook Graph Search
- 上記のハイブリッド
"Things, not strings"
| From | To | Requires |
|---|---|---|
| ターム (term) | 概念 (concept) | パース (parsing)、曖昧性解消 (disambiguation)、共参照解析 (coreference) |
| タームの同一性 (term identity) | 含意 (entailment) | 概念の関係性 (concept relations) |
| 共起 (co-occurrence) | 構文的関係 (syntactic relation) | 文書構造、パース (parsing) |
| タームインデックス (term index) | 意味インデックス (semantic index) | 概念の曖昧性解消 (concept disambiguation)、推論 (inference) |
行動と意図
エンティティの曖昧性解消とリンキング
- エンティティが identify されていることが必要
- 固有表現抽出 (named entity recognition; NER)(例: Stanford NER)
- 曖昧性の解消
Siri のアプローチ
- クエリの意味表現 (semantic representation) を構築
- 時刻、日付、場所、エンティティ、数量
- このセマンティクスで構造化データベースにクエリ
- 地理空間データベース
- オントロジー(Wikipedia の infobox、dbPedia、WordNet、Yago)
- レストランのレビュー情報や予約サービス
- 科学データベース
- Wolfram Alpha
テキストベース質問応答
- 質問処理 (question processing)
- パッセージ検索 (passage retrieval)
- 回答処理 (answer processing)
IBM Watson
- ハイブリッドアプローチ
- クエリの浅い (shallow) 意味表現を構築
- 情報検索の手法で回答候補を生成
- オントロジーや半構造化データで augment している
- よりリッチな知識情報を使って、各候補をスコア付けする
- 地理空間データベース
- 時間の推論 (temporal reasoning)
- タクソノミー (taxonomical classification)
言語から知識へ
単語アラインメント
- Wen-tau Yih et al. 2013. Question Answering Using Enhanced Lexical Semantic Models
- 単語のアラインメント(対応関係)があると仮定

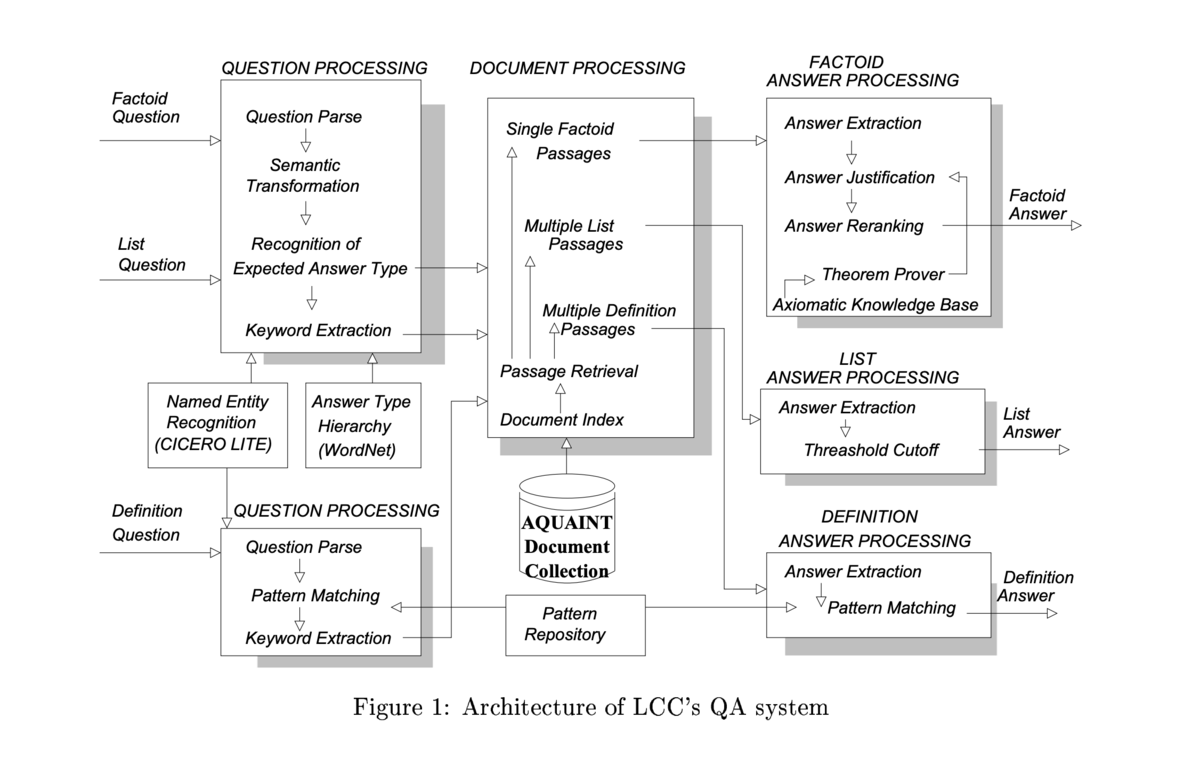
LCC の質問応答システム
Open-domain Question Answering
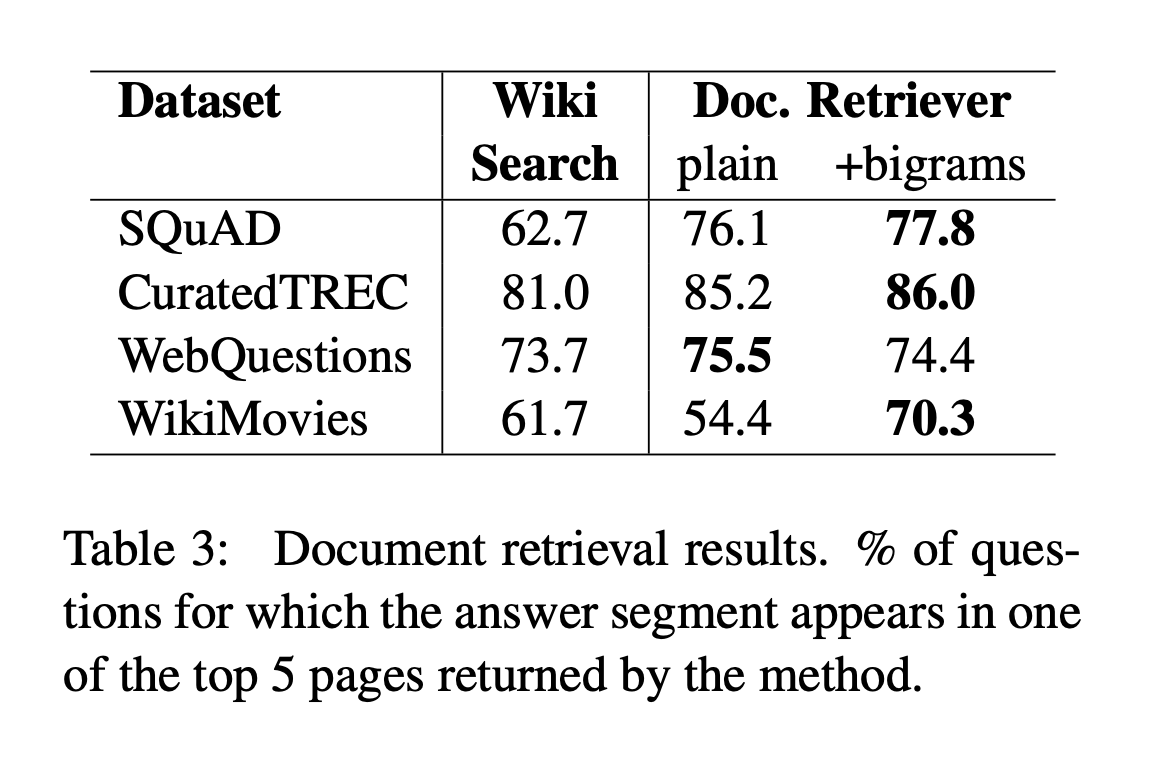
- Chen et al. 2017. Reading Wikipedia to Answer Open-Domain Questions
- 質問応答システム DrQA
- open-domain question: 該当する Wikipedia の記事内の範囲を返すタスク
- 適合する記事の検索 (document retriever) + その記事のテキスト理解 (document reader)

- 古典的な TF-IDF とバイグラムのハッシュを組み合わせると document retriever の性能が上がった