Information Retrieval and Web Search まとめ(14): 評価(1)
前回は、確率的生成モデルから導出された重み付け手法である Okapi BM25 について解説した。今回から検索システムの評価について説明する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の14日目の記事です。
適合性判定
適合性を評価するためには、以下の3つを含むデータが必要:
- 1 . 文書コレクション
- 2 . クエリ集合
- 文書に関連するものであること
- 実際のユーザの情報ニーズを表現していること
- 文書からタームをランダムに抜き出してクエリとするのはよくない
- クエリログからサンプリングする(もし可能なら)
- クエリログが十分に得られない場合は、エキスパートが手で「ユーザの情報ニーズ」を作る
- 3 . クエリと文書の各ペアについて、適合しているかしていないかの判定データ
- 通常は二値で評価
(0, 1, 2, 3, ...)のように段階的なものも使われる- 文書数 500 万、5万クエリのデータあったとき、2500億の判定が必要になる
- 2.5 秒で 1 つの判定をしたとしても、 1011 秒かかる
- 時間あたり 10 ドル支払うとすると 3 億ドルかかる

- 近年のデータセット(GOV, ClueWeb 等)には、数億の Web ページが含まれる
(参考: IIR 8.1, 8.5)
検索システムの評価
- ユーザの情報ニーズは、クエリに翻訳される
- 適合性はクエリに対してではなく、ユーザの情報ニーズに対して判定される
- 例
- 情報ニーズ: "My swimming pool bottom is becoming black and needs to be cleaned."
- クエリ: "pool cleaner"
- 文書が根本的な情報ニーズに対応しているかどうかによって判定する
- 単語が含まれているかどうかは見ない
(参考: IIR 8.1)
ランクなし検索の評価:精度と再現率
- 精度 (precision)
- 検索された文書のうち、適合するものの割合
- 再現率 (recall)
- 適合する文書のうち、適合するものの割合
- 以下の分割表を使うときれいに整理できる:

- 精度
- 再現率
(参考: IIR 8.3)
ランクつき検索評価指標
- 二値適合性
- Precision@K
- Mean Average Precision (MAP)
- Mean Reciprocal Rank (MRR)
- 多値適合性
- Normalized Discounted Cumulative Gain (NDCG)
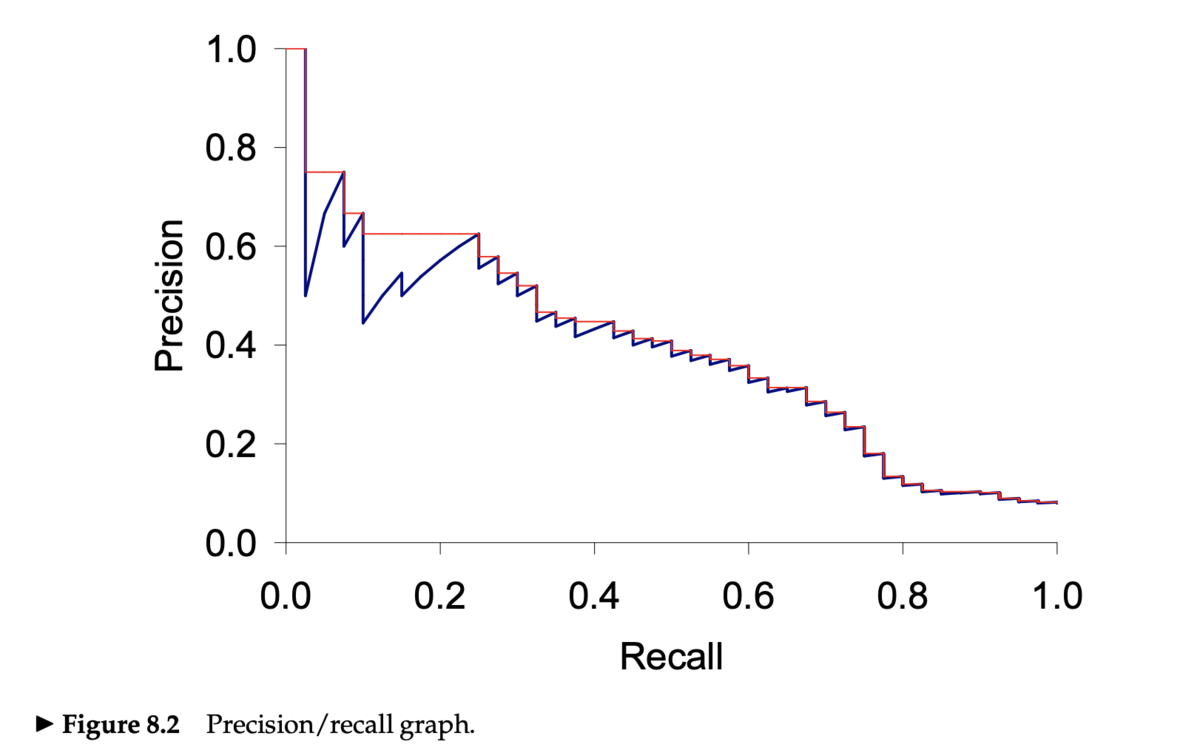
再現率-精度曲線
Precision@K
- 順位(ランク)の閾値を K とし、上位 K 件までの文書で適合するものの割合
- K より下の文書は無視する
- 以下のような Top-4 の検索結果があったとすると
1: relevant2: nonrelevant3: relevant4: nonrelevant
- Precision@K は以下の通り
P@3 = 2/3P@4 = 2/4P@5 = 3/5
- 同様に Recall@K も定義できる
Mean Average Precision (MAP)
- 適合している各文書の順位を考慮する
- その順位に対して Precision@K をそれぞれ計算する
- 平均精度 (Average Precision; AP) は、計算されたすべての P@K の平均 (average)
- Mean Average Precision (MAP) は、複数のクエリに対して Average Precision を計算し、その平均 (mean) をとったもの

- 適合する文書がなかった場合、精度は 0 と仮定する
- MAP はマクロ平均
- 各クエリは等しくカウントされる
- MAP は研究論文でおそらくもっとも一般的に使用されている評価指標
- MAP は、ユーザが多くの適合文書を見つけたいと考えていることを想定している
- MAP は非常に多くの適合性判定を必要とする
講義資料
参考資料
- IIR chapter 8
- MG section 4.5
- MIR chapter 3