Information Retrieval and Web Search まとめ(25): パーソナライズ
前回は、質問応答とその手法(テキストベース、ナレッジベースを使った方法、それらのハイブリッド)について説明した。今回はパーソナライズについてまとめる。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の25日目の記事です。
パーソナライズ
クエリの曖昧性とパーソナライズ
- 短いクエリではユーザの情報ニーズを明確に表現できない
- たとえば
chiは以下のような意味をもつ- Calamos Convertible Opportunities & Income Fund quote
- The city of Chicago
- Balancing one’s natural energy (or ch’i)
- Computer-human interactions
- つまり、1つのランキングでは、すべてのユーザに最適なものにはできない
- パーソナライズドランキング (personalized ranking) がそのギャップを埋めるただ1つの方法
- パーソナライズに以下のような情報を使うことができる:
- ユーザの長期的な振る舞い(ユーザの長期的な興味を判定するため)
- 短期的なセッション情報(ユーザの現在のタスクを判定するため)
- ユーザの位置情報
- SNS (social network)
- ...
パーソナライズのポテンシャル
- [Teevan, Dumais, Horvitz 2010]
- RQ
- パーソナライズすることによってどのくらいランキングを改善できるか?
- そして、それをどのように計測するか?
- 評価者 (rater) に明示的に検索結果のレーティングを付けてもらう
- ただし、評価者にユーザの情報ニーズが何であったか予想してもらうのではなく、個人的な考えで適合しているかどうかの観点で評価
- 各クエリ q に対して
- 各検索結果の平均レーティングを計算
- 平均レーティングを使って最適ランキング
を決定
- 各評価者 i に対して、ランキング
- そうして計算された各評価者の NDCG の平均
を計算
- すべてのクエリでの
とする
- パーソナライズのポテンシャルを
とする

パーソナライズド検索の概要
- [Pitkow et al. 2002]
- パーソナライズド検索 (personalizing search) の2つの一般的な方法
- クエリ拡張 (query expansion)
- ユーザのクエリを、ユーザの意図 (intent) に応じて修正 (modify) もしくは拡張 (augment) する
- 例: IR --> "information retrieval", "Ingersoll-Rand"
- リランキング (reranking)
- 同じようにクエリを発行し、検索結果を取得したあと、それを並べ替える
- パーソナライズされた結果を得ることも、全体的に適合する (globally relevant) 結果を得ることもできる
- クエリ拡張 (query expansion)
ユーザ意図
- ユーザによって与えられたもの
- ときには役立つ(とくに新しいユーザの場合)
- ユーザの振る舞いやユーザのデータから推論されたもの
- 過去に発行されたクエリ
- 過去に訪れた Web ページ
- 個人の文書データ
- プライバシーを守ることが非常に重要
適合性フィードバックによるパーソナライズ
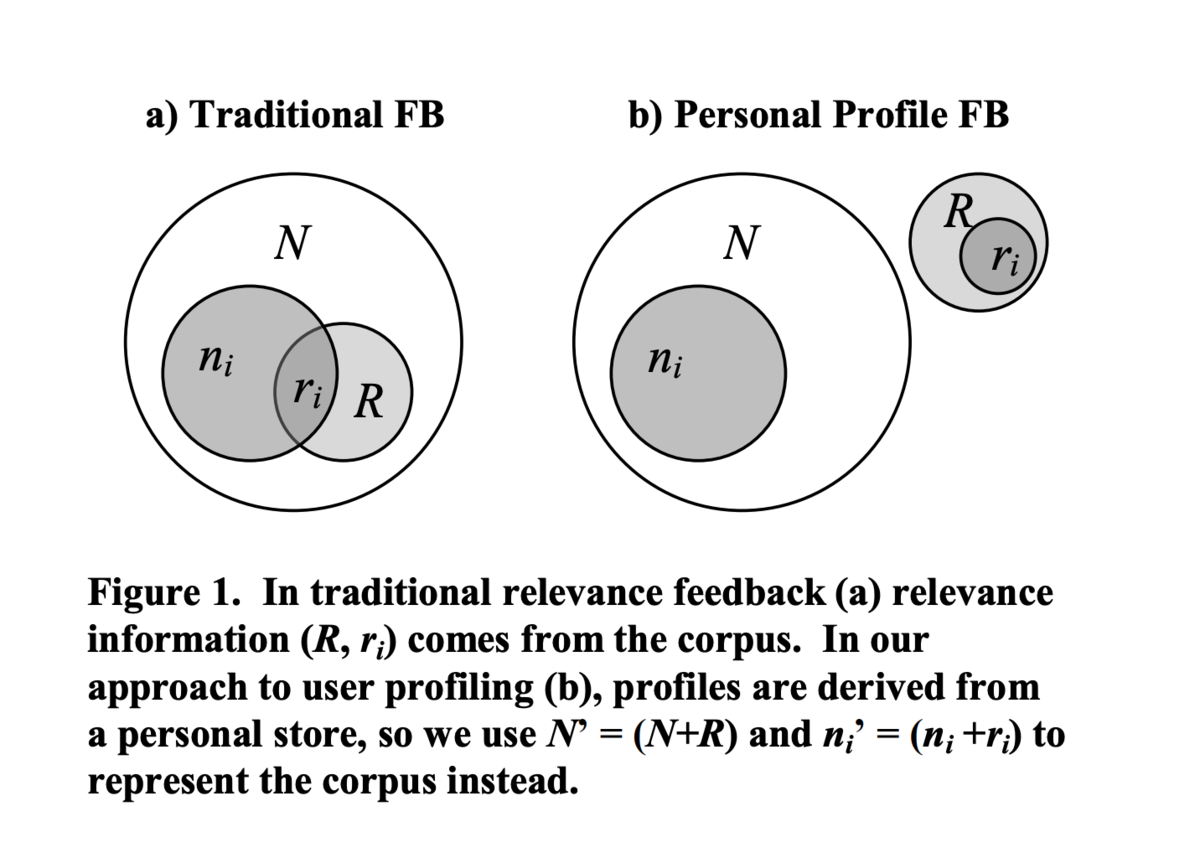
- 古典的な適合性フィードバック (traditional relevance feedback)
: コーパスの文書数
: ターム i を含む文書数
: 適合する文書数
: ターム i を含み、かつ適合する文書
- 個人プロファイル適合性フィードバック (personal profile relevance feedback)
リランキング
- スコア関数として、BM25 を変えたものを使う
- スコア関数は以下の形のものを使う:
はタームが文書中に出現した頻度 (term frequency)
はそのタームの重み (term weight)
- 古典的な適合性フィードバック ([Teevan+ 2005] Figure 1a) では、タームの重み
と
を使って、ユーザデータを使った適合性フィードバック ([Teevan+ 2005] Figure 1b) でのターム重み
コーパスの表現
ユーザの表現
- ユーザが閲覧したページ
- ユーザが閲覧したり送信した Email
- カレンダーの予定
- クライアントマシン上の文書
文書とクエリの表現
- 文書はタイトルとスニペットで表現される
- クエリは、クエリ文字列の近くに出現した単語で拡張される
- もとのクエリが cancer だったとき、以下の下線の単語がクエリになる
The American Cancer Society is dedicated to eliminating cancer as a major health problem by preventing cancer, saving lives, and diminishing suffering through...
Personalized PageRank
- [Haveliwala 2002]
- [Jeh and Widom 2003]
- 通常の PageRank では、すべてのページにおいてテレポート確率ベクトル (teleportation probability vector) p は一様 (uniform) だった
- ユーザの嗜好 (preference) をその p によって表現する
- ユーザがどのページにテレポートするかが、ユーザによって変わる
- p はユーザのブックマークにあるページのなかで一様とする
- もしくは、ユーザが興味をもっているトピックのページについてはテレポート確率が存在することにする
- しかし、 Personalized PageRank を計算するのは高コスト
Linearity theorem
- 任意の preference vector
と
に対して、
と
がそれぞれに対応する personalized PageRank vector だとする
- このとき、
となる任意の非負の定数
,
に対して以下が成り立つ
Topic-sensitive PageRank
クエリタイミングでの計算
- クエリのトピックに対する分布を構築する
- ユーザプロファイルからトピックの分布を計算
- 他のコンテキスト情報も使える
- トピックの preference を使って、topic PageRank vector の重み付き線形和を計算し、それを通常の PageRank の代わりに使う
ソーシャルネットワークでのパーソナライズド検索
- [Curtiss et al. 2013]
- Unicorn: Facebook Graph Search のバックエンド
- Facebook Graph Search
- ノード (node) は人やもの(エンティティ)を表す
- エンティティ (entity) はユニークな 64 ビットの
id - エッジ (edge) はノード間の関係 (relationship) を表す
- エッジの種類は数千タイプある:
friendlikeslikers...
- エッジの種類は数千タイプある:
Unicorn のデータモデル
- ノード数は数億だが、グラフは疎 (sparse)

Unicorn の基本的な集合演算
- クエリ言語は基本的な集合演算をサポートしている
andordifference
- 例1:
id 5かid 6どちらかの友達(or(friend:5 friend:6))
- 例2:
id 5の女性の友達で、id 6の友達ではない人(difference (and friend:5 gender:1) friend:6)
サジェスト (Typehead)
- 最初の数文字を入力するだけでユーザを見つける
- インデックスサーバは、ある一定の文字数までのすべての名前の接頭辞 (prefix) に対してポスティングリストを持っている
- 他の演算子と組み合わせられる
- 例:
(and mel* friend:3)
- 例:
weak-and 演算子
- Unicorn は
weak-andという特殊な演算子をサポートしている optional-hitsoptional-weightというオプションをもつ- その条件が満たされていなくてもよいという意味

(weak-and (term friend:3 :optional-hits 2) (term malanie) (term mars*))の検索:optional-hits 2は、2件まで、この条件(1つめのterm)が満たされていなくても結果に含める、という意味- 検索結果は
2078864となる 62は返されない- 3 つの
term条件の全てを満たしているのは7と64だけ - 左から順番に見ていって、
20と88は条件を 2 つしか満たしていないが、この2つまでは検索結果に含まれる 62に達したときにはすでにoptional-hitsの2を使い果たしているので、これは含まれない
講義資料
参考資料
- J. Teevan, S. Dumais, E. Horvitz. Potential for personalization. 2010
- J. Pitkow et al. Personalized search. 2002
- J. Teevan, S. Dumais, E. Horvitz. Personalizing search via automated analysis of interests and activities. 2005
- P. Bennett et al. Inferring and using location metadata to personalize Web search. 2011
- T. Haveliwala. Topic-sensitive pagerank. 2002. (PDF)
- G. Jeh and J. Widom. Scaling personalized Web search. 2003(PDF)
- M. Curtiss et al. Unicorn: A system for searching the social graph. 2013(PDF)