Information Retrieval and Web Search まとめ(11): スコア計算:TF-IDFとベクトル空間モデル
前回は、Noisy channel モデルによるクエリのスペル訂正について説明した。今回は、文書のスコアリングとそのモデルについて書く。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の11日目の記事です。
ランク付き検索
ブーリアン検索の問題点
- ここまでは単なるブーリアンクエリを扱ってきた
- 文書がマッチするかどうかだけ見ていた
- 情報ニーズやコレクションに関して深く理解しているエキスパートユーザにとっては十分
- アプリケーションにもよる
- だが、ほとんどのユーザにとっては適切ではない
- ほとんどのユーザはブーリアンクエリを組み立てられない(もしくはできても面倒)
- 数千件もある検索結果を全部見ていきたくない
- とくに Web 検索では検索結果が多い
- ブーリアンクエリの検索結果は、しばしば非常に少なくなる(=0)か、非常に多くなる(>1000)
- "standard user dlink 650" --> 200,000 件
- "standard user dlink 650 no card found" --> 0 件
- 適切な件数の検索結果を得るにはスキルが必要
ランク付き検索モデル
- ランク付き検索 (ranked retrieval) では、クエリに対して、コレクション内の上位の文書を順序付きで返す
- クエリは演算子(AND, OR, NOT など)や式ではなく、単語から構成されるフリーテキストで書かれることもある
- ランク付きの検索結果が得られれば、検索結果が膨大になっても問題にならない
- ユーザは上位 k (~ 10) 件の結果を見る
- ただし、ランキングアルゴリズムが有効に働いているという仮定のもと
- スコアリングがランク付き検索の基礎
- ユーザにとって有用と思われる文書を順番に返したい
- クエリに対して文書をどうやって順序付けすればよいか
- 各文書にスコア(たとえば
[0, 1]の範囲で)をつける - このスコアがクエリと文書がどのくらい「適合 (match)」しているかを表す
- 各文書にスコア(たとえば
文書のスコア計算
Bag of words モデル
- Bag of words モデル は、タームの出現回数を考慮する文書のモデル
- ただし、単語の出現した順番は考慮しない
- 以下の2つは Bag of words モデルでは同じになる
- "John is quicker than Mary"
- "Mary is quicker than John"
- 位置インデックスではこれらの2つを区別できたが、Bag of words モデルではできない
- ただし、単語の出現した順番は考慮しない
- 以下の議論では、文書もクエリもこの Bag of words モデルを基本とする
クエリと文書の適合度
- クエリと文書のペアに対してスコアを付けたい
- 1タームのクエリで考える
- もし、文書中にそのタームがなければ、スコアは 0(古典的には)
- 文書中にたくさんそのタームが出現していれば、そのぶんスコアは高くなる(べき)
Jaccard 係数
- Jaccard 係数 (Jaccard coefficient) は、集合どうしの重なり(共通部分)の代表的な指標
- 集合 A, B に対して以下のように定義される
- A と B の要素数は同じでなくてもよい
- Jaccard 係数は 0 から 1 の間の値を取る
- 集合 A, B に対して以下のように定義される
- 文書とクエリそれぞれについて、それぞれが含むタームを要素とする集合と考え、各ペアの Jaccard 係数を計算することができる
- それによってクエリ-文書ペアをスコアリングする
- Jaccard 係数の問題点
- 文書中のターム頻度 (term frequency; TF) (文書中にタームが出現する回数)を考慮していない(ターム頻度については後述する)
- あまり出現しない単語は、頻出語よりも情報量が多いはずだが、Jaccard 係数はこれを考慮に入れない
- 長さの正規化に関してもっと賢い方法が必要
タームの重み付け
ターム-文書カウント行列
- Information Retrieval and Web Search まとめ(2): 転置インデックスで説明した、ターム-文書接続行列 (term-document incidence matrices) を思い出す
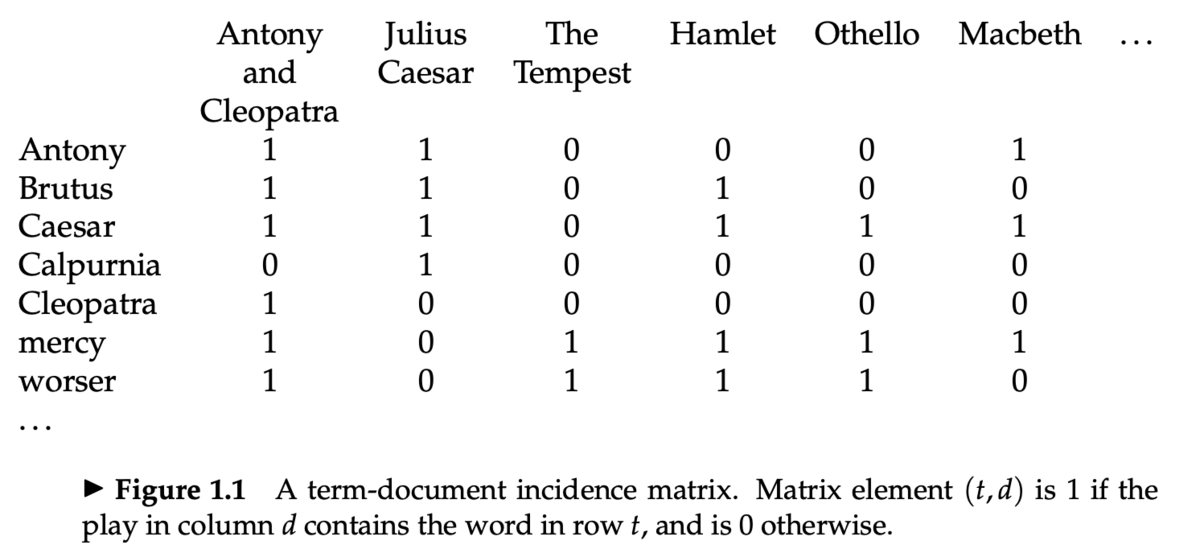
- 各文書(この行列の列にあらわれている作品)は、2値ベクトル
で表現される
- 次に、この行列の要素を、タームの出現回数で置き換える
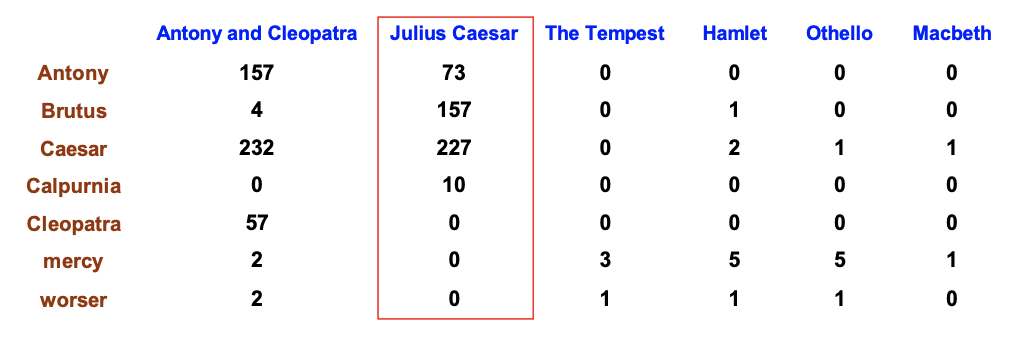
- 各文書は、カウントベクトル
で表現される
ターム頻度 (TF)
- ターム頻度 (term frequency; TF)
は、文書
内のターム
に対して定義され、
- この tf をクエリと文書の適合スコアを計算するのに使いたい
- だが、tf そのものは求めているものではない
- タームが 10 回出現する文書は 1 回出現する文書より適合していると考えられる
- だが、10倍も適合しているわけではない
- 適合度は tf に線形に増えるわけではない
- 対数頻度重み付け (log-frequency weighting) により、この問題を緩和する
- tf と、対数頻度重み付けした tf は以下のようになる
- 0 --> 0
- 1 --> 1
- 2 --> 1.3
- 10 --> 2
- 1000 --> 4
- 文書-クエリペアのスコアリング
- クエリ
と文書
- 文書中にクエリ内のタームがひとつも出現していなかった場合、スコアは 0
- クエリ
コレクションの統計情報
- レアなタームは頻出するタームよりもより有用 (informative) であるはず
- 例: arachnocentric のような単語
- そこで、コレクションの中での希少度を考慮に入れる
- レアなタームにはより大きい重み付けをする
- コレクション頻度 (collection frequency) cf は、コレクション中にターム t が出現する回数
- 文書頻度 (document frequency) df は、ターム t を含む文書の数

逆文書頻度 (IDF)
- ターム t の逆文書頻度 (inverse document frequency) idf を以下のように定義する
- idf の効果をなめらかにする (dampen) ために log をとる
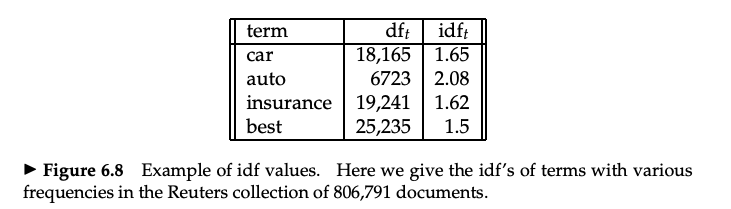

- ランキングにおける idf の効果
- 1タームのクエリに対しては idf は効果をもたない
capricious personというクエリがあったとき、idf はpersonよりもcapriciousに大きい重みを与える
TF-IDF 重み付け
- TF-IDF 重み付けは、以下のように tf と idf の積によって重みを定義する
- TF-IDF は、情報検索において最もよく知られている重み付けの1つ
- 他に有名なものとしては BM25 がある(後日紹介)
- 文書中のタームの出現回数が多いと大きくなる
- コレクション中のタームの希少度が高いと大きくなる
- クエリ q が与えられたときの文書 d のスコアは以下のように計算する
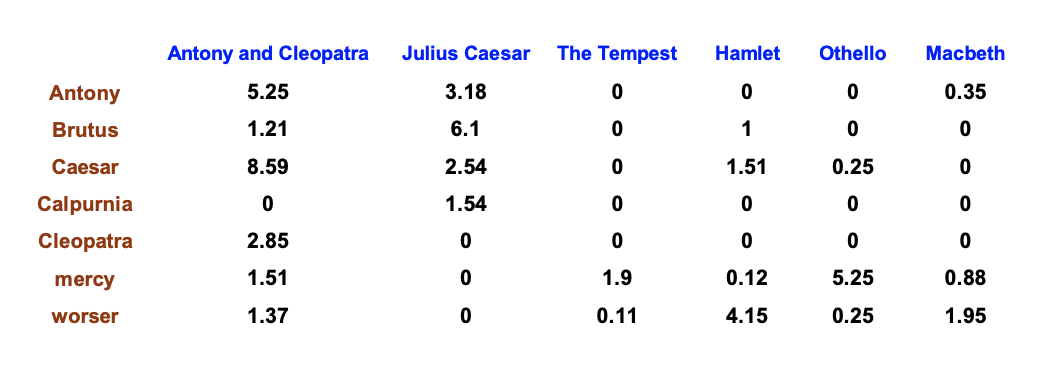
- TF-IDF によってターム-文書カウント行列は、以下のようなターム-文書重み行列となる
- 各文書は、重みベクトル
で表現される
ベクトル空間モデル
文書ベクトル
- ここまで、文書をベクトル
として表現してきた
- |V| 次元のベクトル空間を考える
- 文書はこの空間での点、もしくはベクトルとなる
- タームはこの空間の軸となる
- この空間は非常に高次元になる
- たとえば Web 検索では、数千万次元になる
- また、このベクトルは非常に疎
- ほとんどの要素は 0
クエリベクトル
- クエリについても、空間内のベクトルとして表現する
- この空間において、クエリベクトルへの「近さ (proximity)」に応じて文書をランク付けする
コサイン類似度
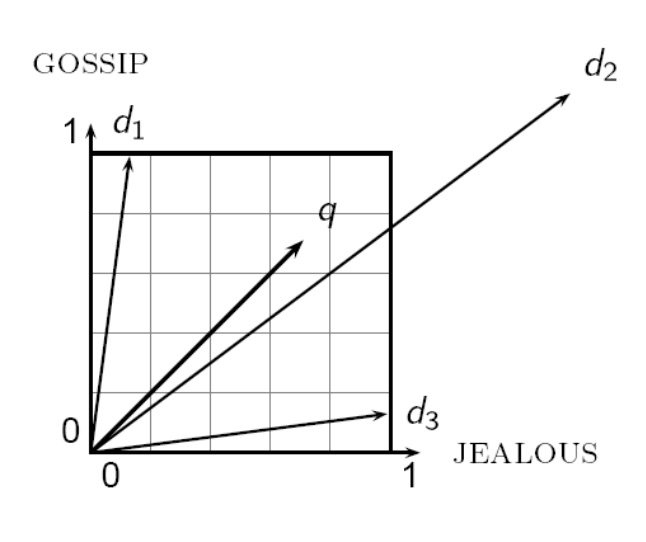
- 距離ではなく、角度 (angle) はどうか?
- 文書 d にそれ自身の単語をすべて足した文書 d' を考える
- 意味的には d と d' は同じものであると考えられるが、ユークリッド距離上は非常に離れたものになる
- d と d' のベクトル同士がなす角度 (angle) は 0
- クエリとの角度の大きさによって文書をランク付けするとよさそう
- 角度ではなく、コサインを使う
- 以下の2つは同じ
- 「クエリと文書の角度の降順で、文書をランク付けする」
- 「
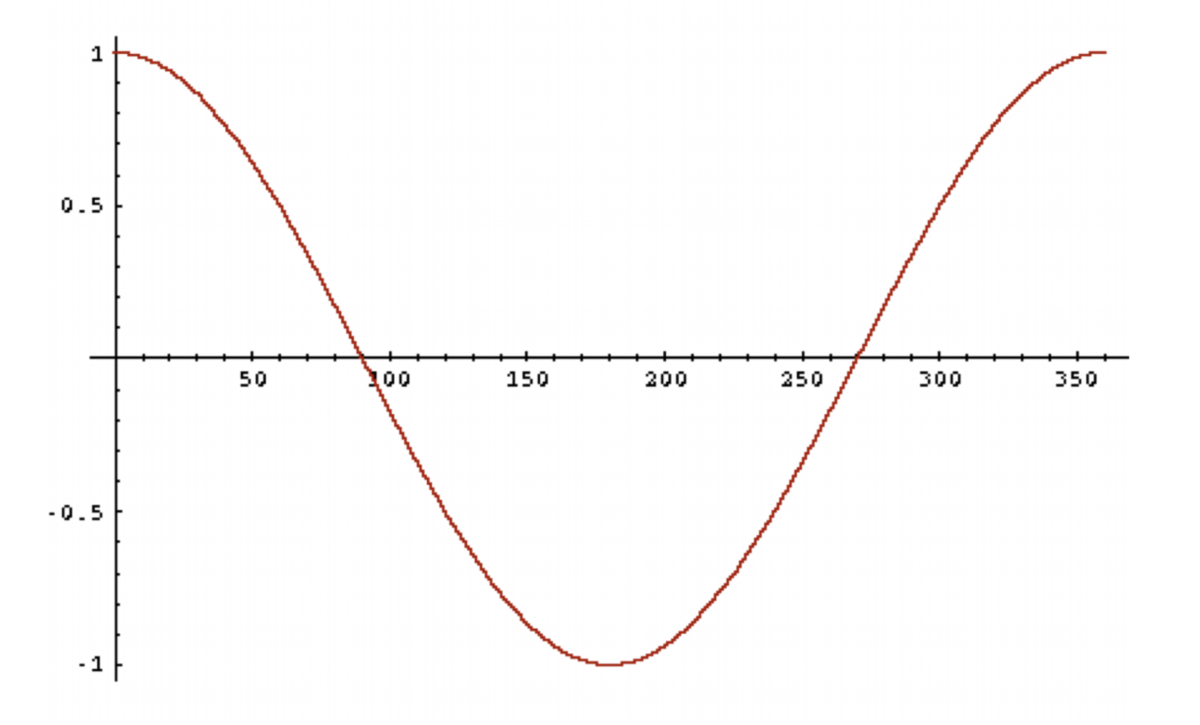
cosine(query, document)の昇順で、文書をランク付けする」 - コサイン関数は
] の区間で単調減少、かつ
] (0° のとき 1、180° のとき -1)の値を取るので、類似度の指標として都合が良い
文書長の正規化
- ベクトルは各成分をその長さで割ることで正規化できる
- 正規化には
ノルムを使う:
- ベクトルをその
- 単位ベクトルは全て半径 1 の単位超球上の点になる
- この正規化により、上記の文書 d と d' (d の単語を2倍にした文書)は同じベクトルになる
- また、長い文書と短い文書も比較しやすくなる
- 文書長による影響を減らすことができる
コサイン類似度の計算
- クエリベクトル
と文書ベクトル
のコサインの計算は以下のようになる
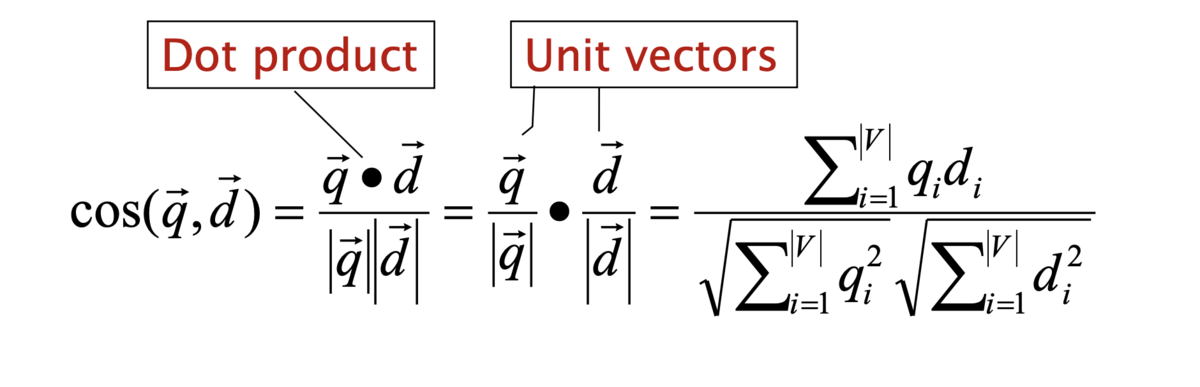
は
ベクトル空間モデルによるスコア計算

- このアルゴリズムは term-at-a-time (TAAT)
- タームごとにスコア計算していく方式
- document-at-a-time (DAAT) にすることもできる
- ポスティングごとに重み
を事前に計算してポスティングリストに保存しておくこともできるがもったいない
- 浮動小数点数なので大きい
- TF-IDF の場合、
(ターム t の逆文書頻度)はポスティングリストの先頭に保存する
- (動的に重み付けを変えることもできる)
- Top-k のアイテムは優先度付きキュー(たとえばヒープ)を使えば高速に抽出できる
TF-IDF のバリエーション
- TF-IDF には、他にも様々な亜種 (variant) がある

- クエリと文書それぞれでタームの重み付けを変えることもできる
- 標準的な重み付けの方法は
- 文書
- ターム頻度 (TF):
logarithm - 文書頻度 (DF):
no idf - 正規化:
cosine
- ターム頻度 (TF):
- クエリ
- ターム頻度 (TF):
logarithm - 文書頻度 (DF):
idf - 正規化:
cosine
- ターム頻度 (TF):
- 文書
講義資料
参考資料
- IIR chapter 6
- 6.2-6.4.3
- Cosine Similarity Tutorial