Information Retrieval and Web Search まとめ(22): Webクローリング
前回は PageRank などのリンク解析手法について説明した。今回は、Web のクローリングを扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の22日目の記事です。
クローリングの概要
- クローラ (crawler) (もしくはスパイダー (spider)、ロボット (robot)、ボット (bot) とも)は、Web ページのリンクを辿り、検索エンジンにページをインデックスするためのコンポーネント
- これらの一連の処理をクローリング (crawling) という
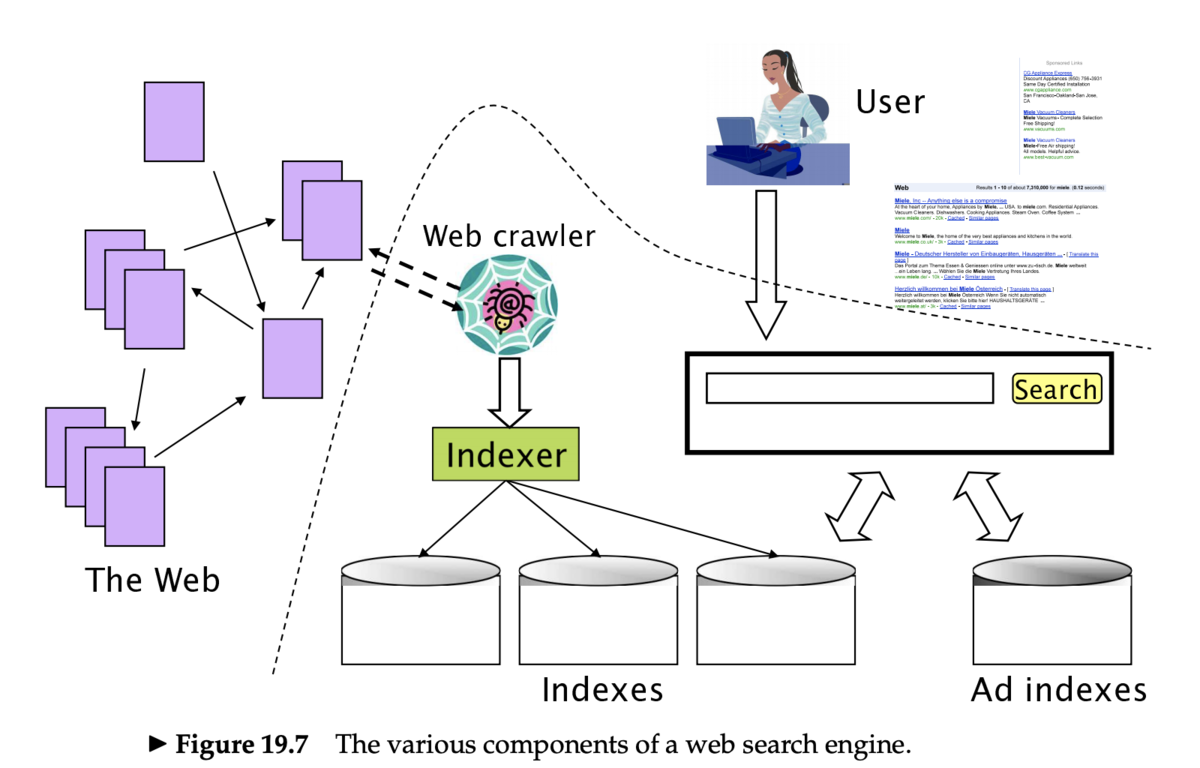
クローラの動作
- 「シード (seed)」となる既知の URL から開始する
- Web ページをフェッチしたあとパースする
- ページに含まれる URL を抽出する
- 抽出した URL をキューに入れる
- キューにある URL をフェッチし、繰り返す
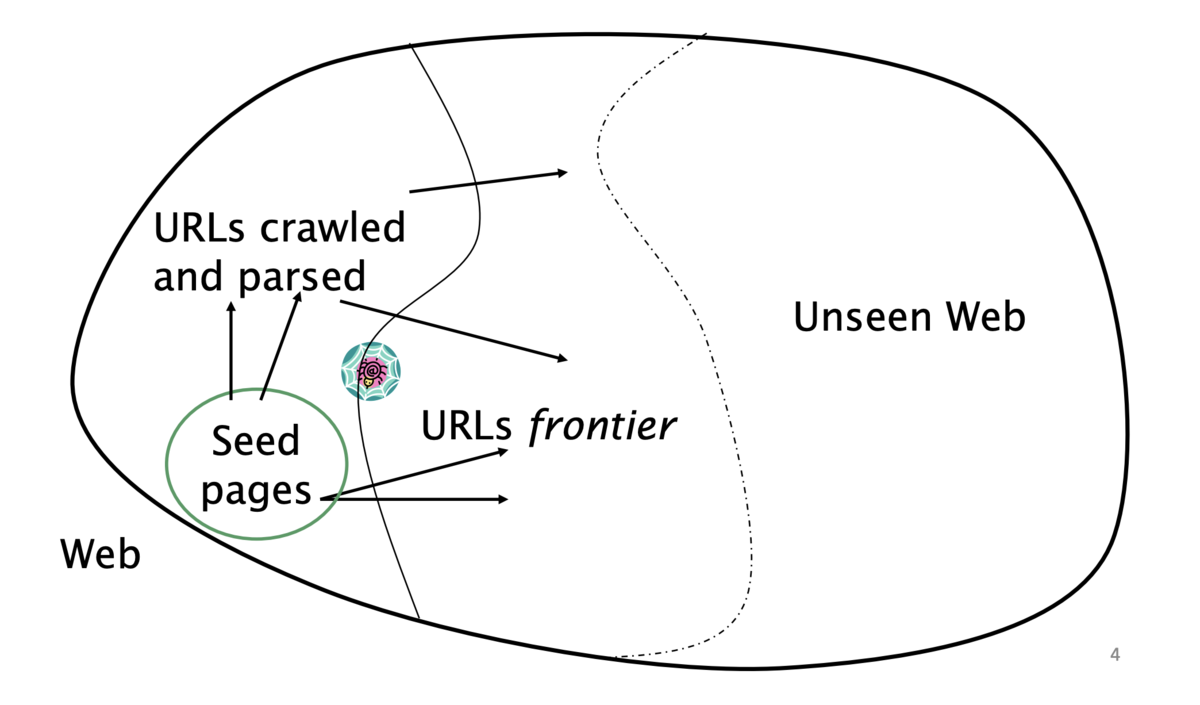
クローリングの難しさ
- Web のクローリングは1台のマシンでは実現不可能
- 上記のすべてのステップは分散化される必要がある
- 悪質なページへの対応
- スパムページ
- スパイダートラップ (spider trap)
- 動的に生成されるページを含む
- リモートサーバへの礼儀正しさ (politeness)
- サーバを高頻度で叩かない
- その他の課題
- リモートサーバのレイテンシや帯域は様々
- ウェブマスターの規定 (webmasters' stipulation)
- サイトの URL の階層をどこまで辿るか
- ミラーサイトや重複ページ
クローラの要件
クローラの MUST 要件
- 頑健 (robust) である
- スパイダートラップや悪質なページから影響を受けないこと
- 礼儀正しい (polite)
- 暗黙的・明示的な礼儀正しさを考慮していること
- 明示的な礼儀正しさ
- クロールするサイトのウェブマスターからの仕様を守る
- 暗黙的な礼儀正しさ
- (仕様になくても)サーバを高頻度で叩かない
robots.txt
- スパイダー(= ロボット)によるアクセスを制限するためのプロトコル (1994-)
- どのページがクロールされるべきで、どのページはされるべきではないのかをアナウンスする
- サーバ側で
/robots.txtファイルを作成する
- サーバ側で
robots.txt の例
searchengineという名前のロボット以外は/yoursite/temp/から始まる URL を訪問してはいけない
User-agent: * Disallow: /yoursite/temp/ User-agent: searchengine Disallow:
クローラの SHOULD 要件
- 分散化されていること
- 複数台のマシンで実行されるように設計されていること
- スケーラブルであること
- マシンを追加することでクロール速度を上げることができるように設計されていること
- 効率的であること
- CPU/ネットワークリソースを使い切れること
- 質の高いページから先にフェッチすること
- 前にフェッチしたページの新しいコピーもフェッチし続けること
- 拡張可能であること
- 新しいデータフォーマットやプロトコルに適応できること
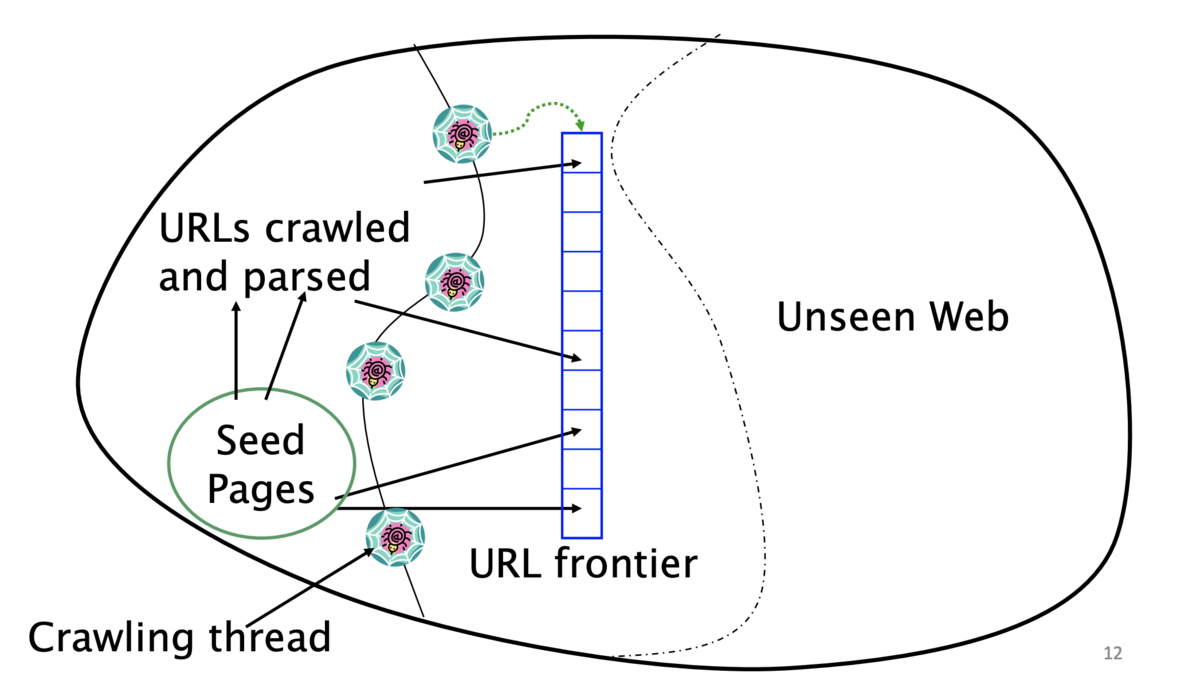
- URL frontier
- 同じホストのページを複数含んでいてもよい
- ただし、同じタイミングでフェッチすることは避けなければならない
- すべてのクローラのスレッドはビジー状態をキープしなければならない
- 同じホストのページを複数含んでいてもよい
クローラのアーキテクチャ
クローラの処理ステップ
- URL frontier から URL を1つ選択する
- その URL をフェッチする
- URL をパースする
- 他の URL を抽出する
- URL がすでに見ているかどうかチェックする
- 見ていなければインデックスに追加する
- 抽出された URL に対して
- フィルタ条件に引っかかっていないか確かめる
- robots.txt のチェックなど
- URL frontier にすでにあるかどうかチェックする
- 重複 URL の排除
- フィルタ条件に引っかかっていないか確かめる
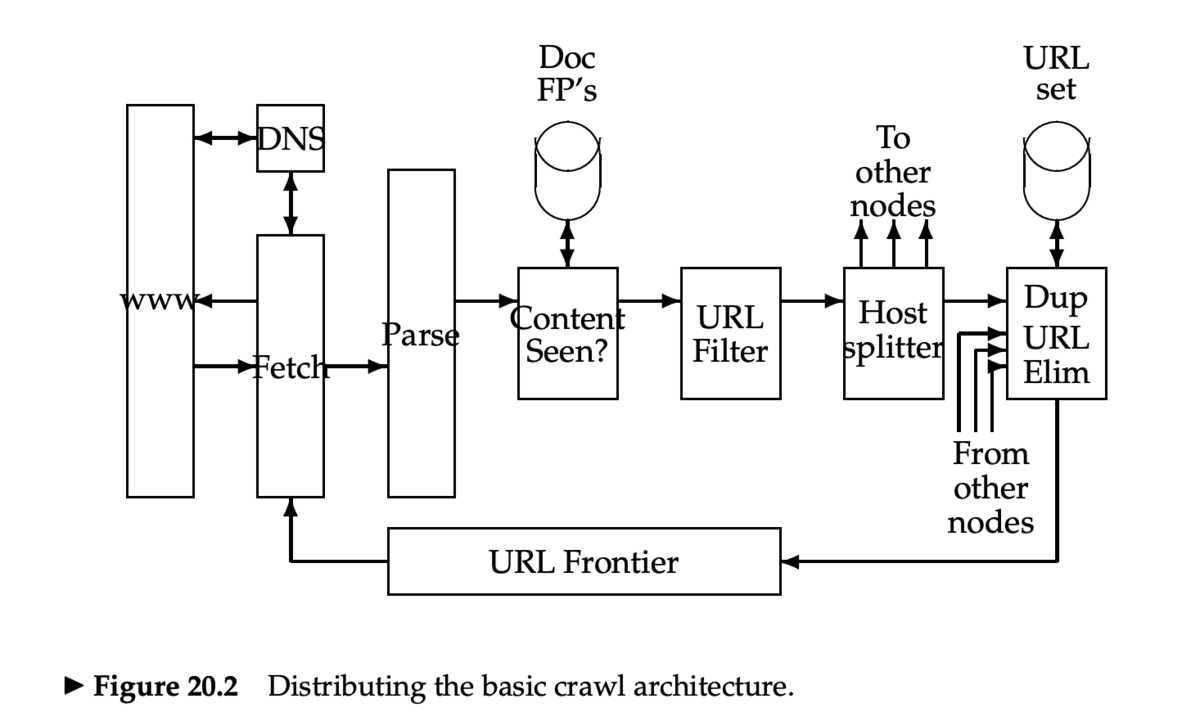
クローラの基本アーキテクチャ
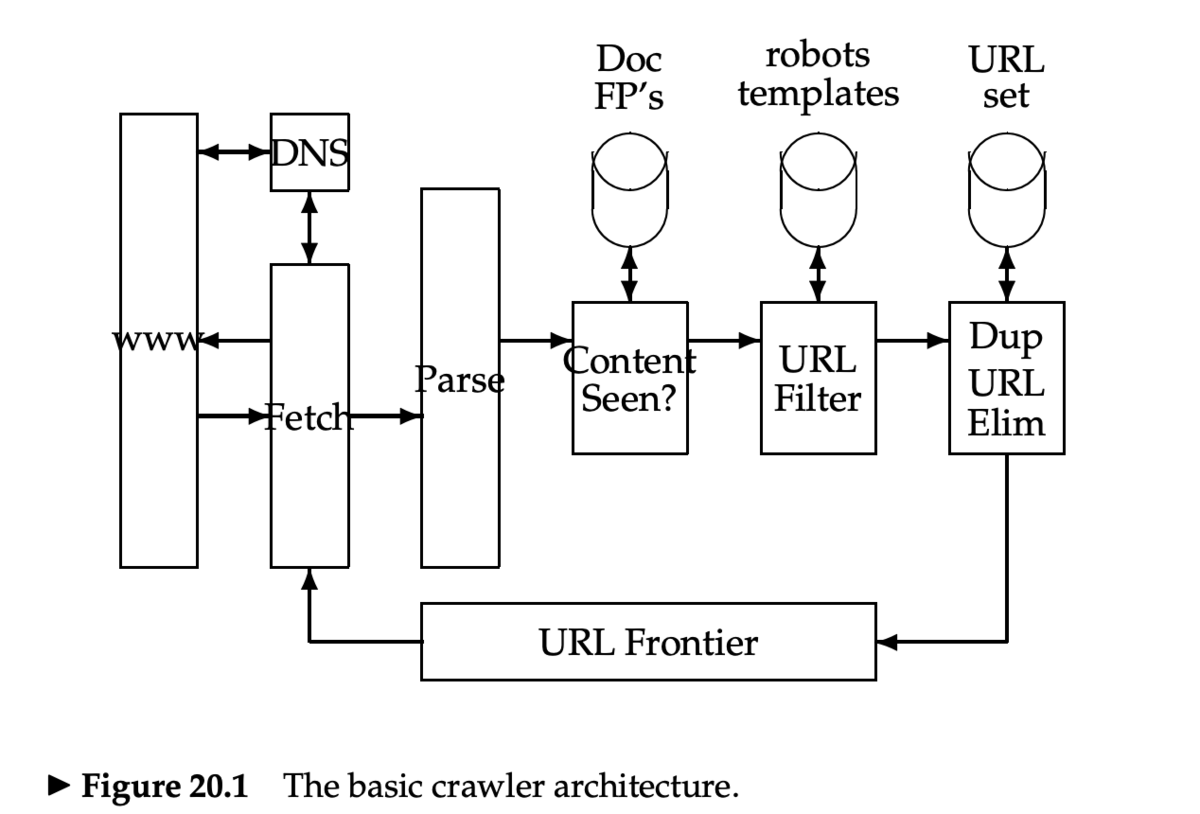
- DNS のルックアップは処理をブロック (blocking) する
- URL 正規化
- URL のパース時に、リンクが相対 URL になっていることがあるので、正規化(展開)する
- 重複ページの判定
- すでに見たページは処理しないようにする
- 文書の fingerprint もしくは shingle を使う
- 次回扱う
- robots.txt
- 1度 robots.txt をフェッチしたら、繰り返しフェッチしないようにする(キャッシュする)
分散型クローラ
URL frontier
- 2つの主な目標
- Politeness: 頻繁に Web サーバを叩きすぎない
- Freshness: いくつかのページは優先的にクロールする
- ニュースサイトのように、頻繁に更新されるページ
- この2つの目標はコンフリクトする
- たとえば、シンプルな優先度付きキューでは不可能
- 多くのリンクが自身のサイトへのリンクなので、アクセスがバーストする
- 一般的なヒューリスティック:前回のリクエストから時間をおいてアクセスする
Mercator URL frontier
- Mercator クローラ [Heydon et al. 1999]
- 多くの研究や商用のクローラの基礎となったクローラの実装 (Java)
- Mercator のスキームは、2つの FIFO キューを使う
- Front queue: 優先度を管理する
- Back queue: Politeness を強制する
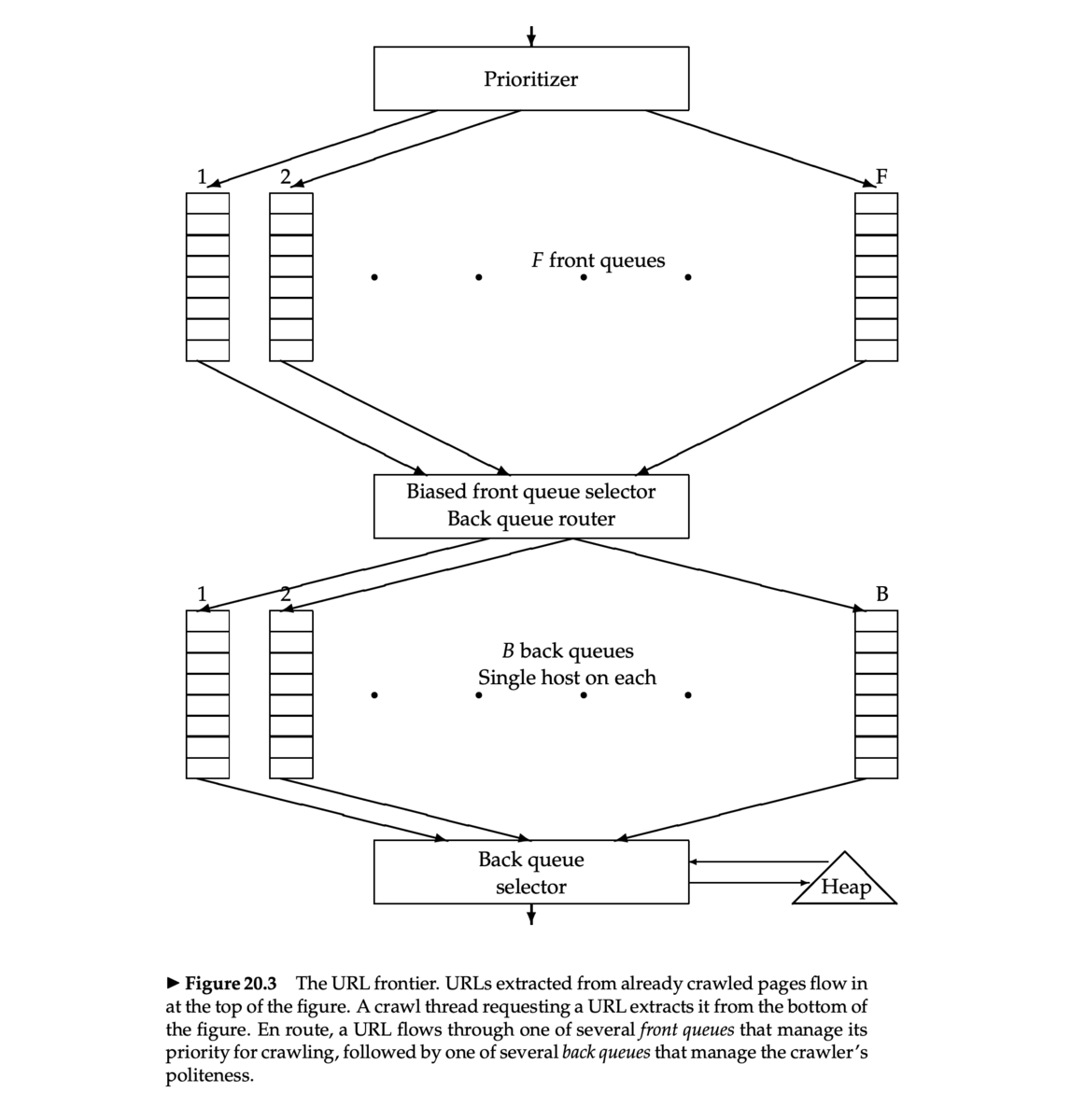
Front queue
- Prioritizer が URL に 1 から F までの優先度を割り当てる
- その URL を、各優先度に対応するキューに append する
- 優先度割当てのヒューリスティック
- 前回のクロール時にリフレッシュレートをサンプルしておく
- アプリケーション依存の方法:サイトの種類(ニュースサイトなど)によって優先度を決める
Biased front queue selector
- Biased front queue selector は、Back queue が URL をリクエストしたとき、その URL を pull するために Front queue を1つ選ぶ
- pull 型なので Back queue がリクエストする
- この選択は優先度でバイアスがかけられたラウンドロビンで行うことができる
- 他のもっと sophisticated な方法を使っても良い
- ランダマイズしてもよい
Back queue
- Back queue はクローリングしているあいだは休まないようにする
- Back queue の数 B で調整(すべてのスレッドがビジーになるように)
- Mercator の推奨設定:クローラスレッド数の3倍
- それぞれの Back queue は1つのホストからの URL のみを含む
- ホスト名から Back queue への対応(マッピング)はテーブルで管理
Back queue heap
- Back queue heap は、1つの Back queue ごとに1つのエントリをもつ
- エントリには、 Back queue に対応するホストが次に叩かれる最も速い時刻を保存
- この時刻は、以下から決定される
- そのホストへの最終アクセス時刻
- 様々な時間バッファのヒューリスティック
Back queue の処理
- クローラスレッドはクロールすべき URL を探す
- Back queue heap のルートを取得
- テーブルをひき、対応する Back queue
qの先頭から URL をフェッチ - Back queue
qが空になったかどうかチェックし、もし空なら Front queue から URLvを pull する- もし URL
vのホストに対応する Back queue がすでにあったら、URLvをそれに append し、別の URL を Front queue から pull し、繰り返す - そうでなければ、
vをqに入れる
- もし URL
qが空でなければ、Back queue heap にそのための新しいエントリを作成する