Information Retrieval and Web Search まとめ(13): 確率的情報検索(2) BM25
前回は、確率的情報検索の基本となる確率的ランキング原理とバイナリ独立モデルについて説明した。今回は確率的モデルによる重み付け手法である Okapi BM25 について解説する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の13日目の記事です。
ベクトル空間モデルの復習
- クエリに含まれる単語が多く出てくる文書の順位は高くすべき
- また、それは文書長などによって調整される
- バイナリ独立モデル(BIM)ではだめなのか?
- 初期の情報検索のモデルの多くは、タイトルや概要(長さがほぼ同じ)を対象にしており、全文検索はあまり意識されていなかった
- ターム頻度を入れたモデルを作りたい
- ベクトル空間モデル(復習)
- クエリと文書を TF-IDF によって重み付けされたベクトルとして表現する
- クエリベクトルと文書ベクトルのコサイン類似度スコアを計算
- 文書をそのスコアによってランク付けする
- 上位 K 件(例えば K = 10)をユーザに返す
Okapi BM25 の概要
- Okapi BM25 は、検索システム Okapi を開発するなかで 25 番目に生まれた、タームの重み付け方法
- BM25 は "Best Match 25" の意味
- TREC で BM25 を採用するチームが増え始めた
- 性能がよい
- BM25 のゴール:パラメータを多く足さずに、ターム頻度や文書長をよく反映すること
- [Robertson and Zaragoza 2009; Spärck Jones et al. 2000]
- BM25 は文書の生成モデル
- 単語(ターム)は多項分布 (multinominal distribution) から独立して生成されると仮定する
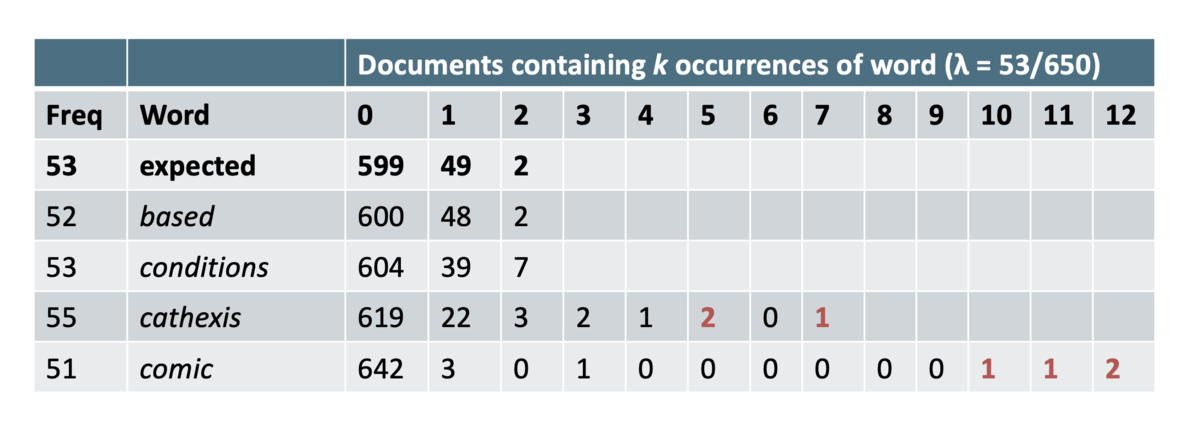
Poisson モデル
- 文書のターム頻度の分布が、ポアソン分布で近似した二項分布に従う、と仮定するモデル
とすることで、二項分布をポアソン分布で近似できる
は二項分布の試行回数、
は試行の成功確率
- Poisson モデルの問題点
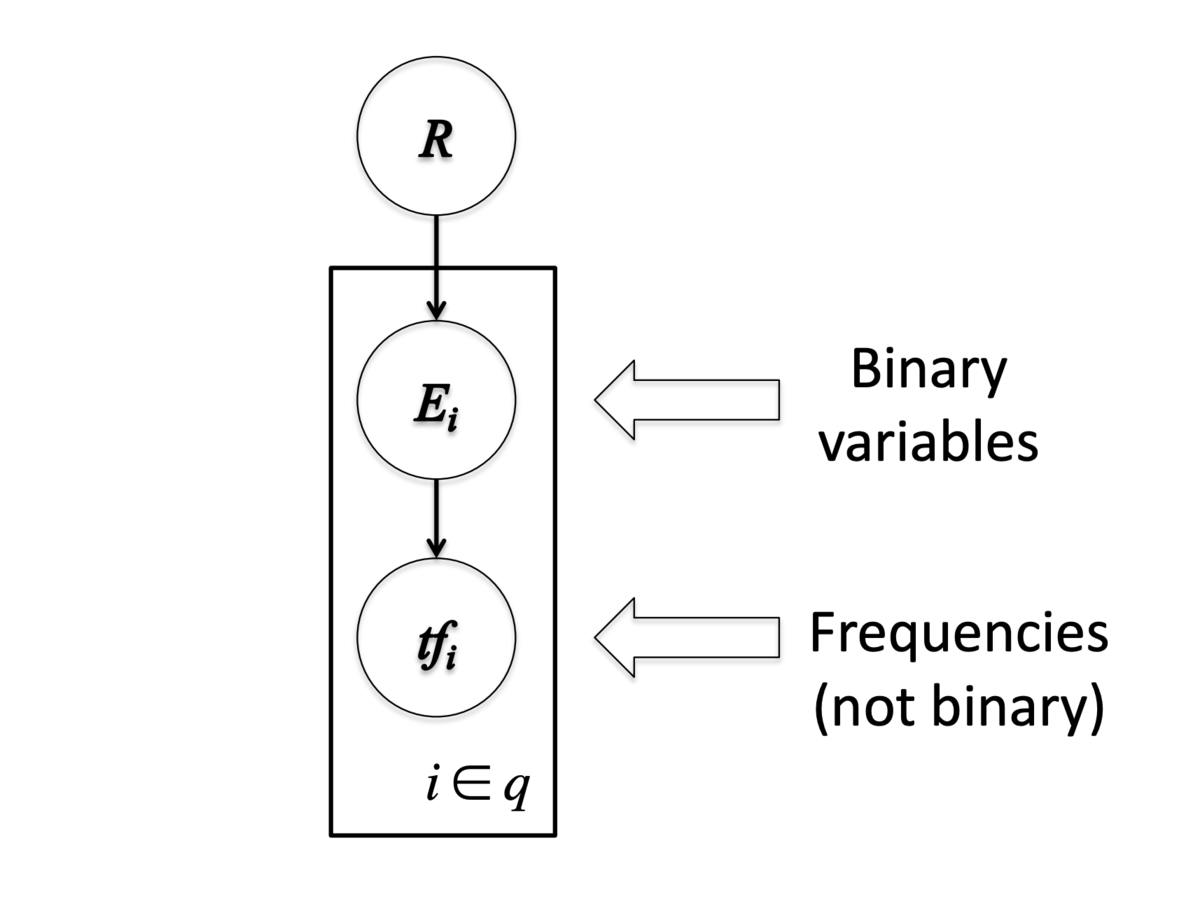
エリートネス
- ターム頻度をエリートネス (eliteness) という概念を使ってモデル化する
- エリートネスとは、文書とタームの組における隠れ変数であり、ターム
に対して
と書くことにする
- 文書中のタームについて、文書がある意味でそのタームで示される概念についての文書であるとき、そのタームはエリート (elite) であるという
- エリートネスは2値で表現する(
or
)
- エリートネスは2値で表現する(
- NFL draft に関する Wikipedia 記事内の、エリートなタームの例(太字)を以下に示す
The National Football League Draft is an annual event in which the National Football League (NFL) teams select eligible college football players. It serves as the league’s most common source of player recruitment. The basic design of the draft is that each team is given a position in the draft order in reverse order relative to its record ...
- タームの出現はエリートネスに依存する
- エリートネスは適合度に依存する
Poisson モデルの Retrieval Status Value
- BIM のときと同様に、Retrieval Status Value (RSV) を考える
- エリートネスを使って
は以下のように展開できる
2-Poisson モデル
- 前述した Poisson モデル(1-Poisson モデルと呼ぶ)の問題を解決するため、2つのポアソン分布でフィッティングする
- 2-Poisson モデルでは、タームがエリートかどうかによって分布が変わる
は文書がタームに対してエリートである確率
、
の値はわからない
2-Poisson モデルの Retrieval Status Value
が満たすべき性質
によって単調に増加
で最大値に漸近的に近づく
- 単に tf をスケーリングするだけではこの性質を満たせない
- 漸近的な極限は
- エリートネスの重み
- 2-Poisson モデルのパラメータ(tex: \pi]、
- --> 上記の性質を満たす、以下の飽和関数で近似する
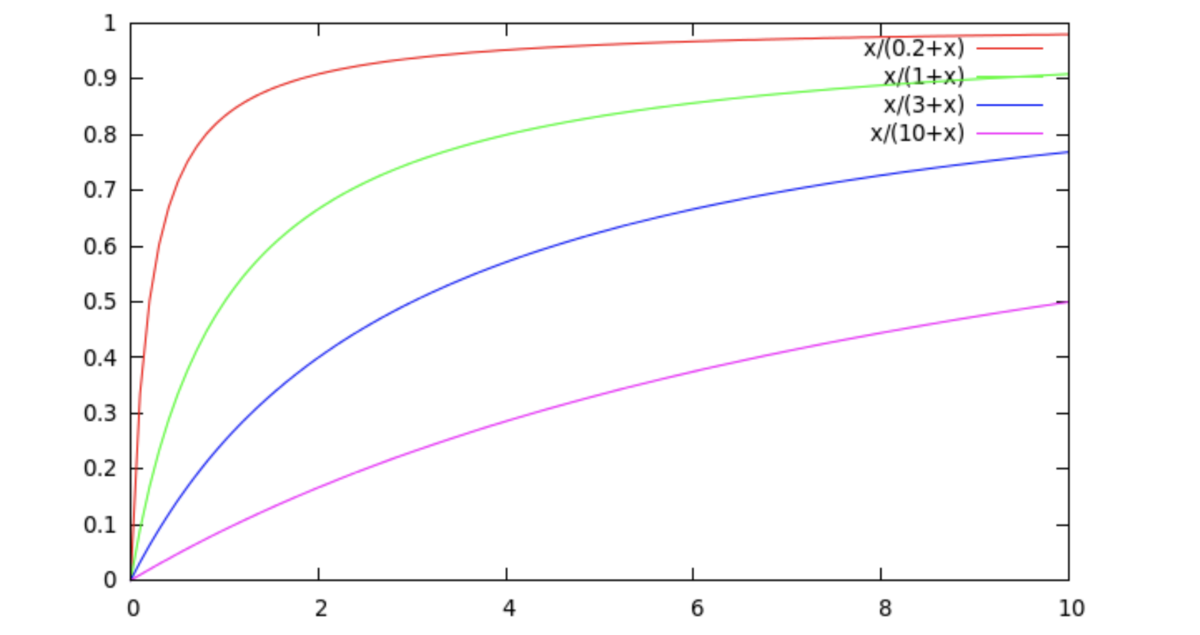
- パラメータが1つしかなくシンプル
が大きいとき (例:
) でも
) には関数はすぐに飽和し、
Okapi BM25
BM25 の原形
- Version 1
- 上記の飽和関数をそのまま使ったバージョン
- バイナリ独立モデル (BIM) に飽和関数をかませる
- Version 2
- BIM を IDF に置き換えて簡略化
は、ランキングを変化させずに
のときにスコアを 1 にするための項
- TF-IDF に似ているが、タームによるスコアは上限がある
文書長による正規化
- 長い文書では
- 文書が長くなっている可能性
- 冗長性:観測された
- 大きいスコープ:観測された
- 冗長性:観測された
- 実際の文書では両方の影響がある
- 部分的になんらかの正規化をする必要がある
- 文書長
- コレクションでの文書長の平均を
とする
- コレクションでの文書長の平均を
- 文書長の正規化を以下で行う
- 正規化の強さをパラメータ b で調整する
- b = 1: 文書長で完全に正規化
- b = 0: 文書長による正規化をしない
BM25
- ターム頻度
- これを使って
を以下のようにする
- よって、BM25 のランキング関数は
のときはバイナリモデルになり、
のときはターム頻度そのものを使うことになる
は文書長の正規化の強さを調整する
のときは正規化なし、
のときは完全に文書長でスケーリングする(相対的なターム頻度を使う)
- 典型的なパラメータ
1.2-20.75
- BM25 のほうがベクトル空間モデルの TF-IDF よりよくなる例
- クエリが
machine learningだったとする - 以下のような文書があったとする
- 文書1:
learningの tf が 1024、machineが 1 - 文書2:
learningの tf が 16、machineが 8 - 文書2 のほうが適合度が高いと思われる
- 文書1:
- TF-IDF:
- 文書1:
11 * 7 + 1 * 10 = 87 - 文書2:
5 * 7 + 4 * 10 = 75
- 文書1:
- BM25(
のとき)
- 文書1:
7 * 3 + 10 * 1 = 31 - 文書2:
7 * 2.67 + 10 * 2.4 = 42.7
- 文書1:
- クエリが
講義資料
- Probabilistic IR: the binary independence model, BM25, BM25F (pdf)
- 5 Term frequency and the VSM
- 6 BM25
- 7 Ranking with features