Information Retrieval and Web Search まとめ(10): スペル訂正
前回は、Permuterm インデックスや k-gram インデックスを使ったワイルドカード検索について解説した。今回は、クエリのスペル訂正を扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の10日目の記事です。
スペル訂正
- スペル訂正の応用
- 文書作成 (MS Word, Google Docs, ...)
- 携帯電話での入力
- Web 検索
- スペルミスの頻度
- アプリケーションによるが、 ~1-20%
- 26%: Webクエリ [Wang et al. 2003]
- 13%: バックスペースなしでのリタイプ(英語とドイツ語) [Whiteelaw et al.]
- 7%: 携帯電話サイズのハンドヘルドで、単語がリタイプで修正されたとき [Soukoreff & MacKenzie 2003]
- 2%: 携帯電話サイズのハンドヘルドで、単語が修正されなかったとき [Soukoreff & MacKenzie 2003]
- 1-2%: リタイプ [Kane and Wobbrock 2007, Gruden et al. 1983]
スペル訂正のタスク
- スペル誤りの検知
- スペル誤りの訂正
- オートコレクト (
hte-->the) - スペル候補のサジェスト
- サジェストリスト
- オートコレクト (
スペル誤りのタイプ
- Non-word(単語ではない)エラー
graffe-->giraffe- Non-word エラーは歴史的には文脈に依存しないものだった
- (古典的には)文脈に依存しない
- Real-word(実単語の)エラー
- タイポエラー
three-->there
- 認識エラー(異形同音異義語 (homophone))
piece-->peacetoo-->twoyour-->you're
- Real-word エラーはほとんど文脈に合わせて訂正する必要がある
- タイポエラー
Non-word スペル誤り
- Non-word スペル誤りの検知
- 辞書に入っていない単語はエラーとする
- (ある一定までは)辞書を大きくすると改善される
- Web 検索ではスペルミスが非常に多いので、大きい辞書の必要性は低い
- Non-word スペル誤りの訂正
- 候補生成
- 元の入力と似ている実単語を候補とする
- もっとも良い候補を選択
- 重み付き編集距離 (weighted edit distance) が最短のもの
- 雑音のある通信路 (noisy channel) での確率が最も高いもの
- 候補生成
Real-word スペル誤り
- 各単語
wについて、候補集合を生成する- 発音が似ているもの
- スペルが似ているもの
wも候補に含める
- 最もよい候補を選択
- 雑音のある通信路でスペル誤りを評価
- 文脈依存
- "Flying form Heathrow to LAX" --> "Flying from Heathrow to LAX"
候補生成
- 以下の基準で候補となる単語を列挙する
- 似ているスペルの単語
- 編集距離が小さいもの
- 似ている発音の単語
- 発音の距離が小さいもの
- 似ているスペルの単語
- 80% の誤りは編集距離 1 まで
- 編集距離 2 まででほとんどの誤りがカバーできる
- 以下のような方法で候補生成ができる
Damerau-Levenshtein 編集距離
- Damerau-Levenshtein 編集距離 (Damerau-Levenshtein edit distance) は、2つの文字列の編集距離を測る尺度の1つ
- 文字の編集
- 挿入
- 削除
- 置換
- 隣接文字交換
- これ以外は Levenshtein 編集距離と同じ
- 編集距離については IIR 3.3.3 節を参照
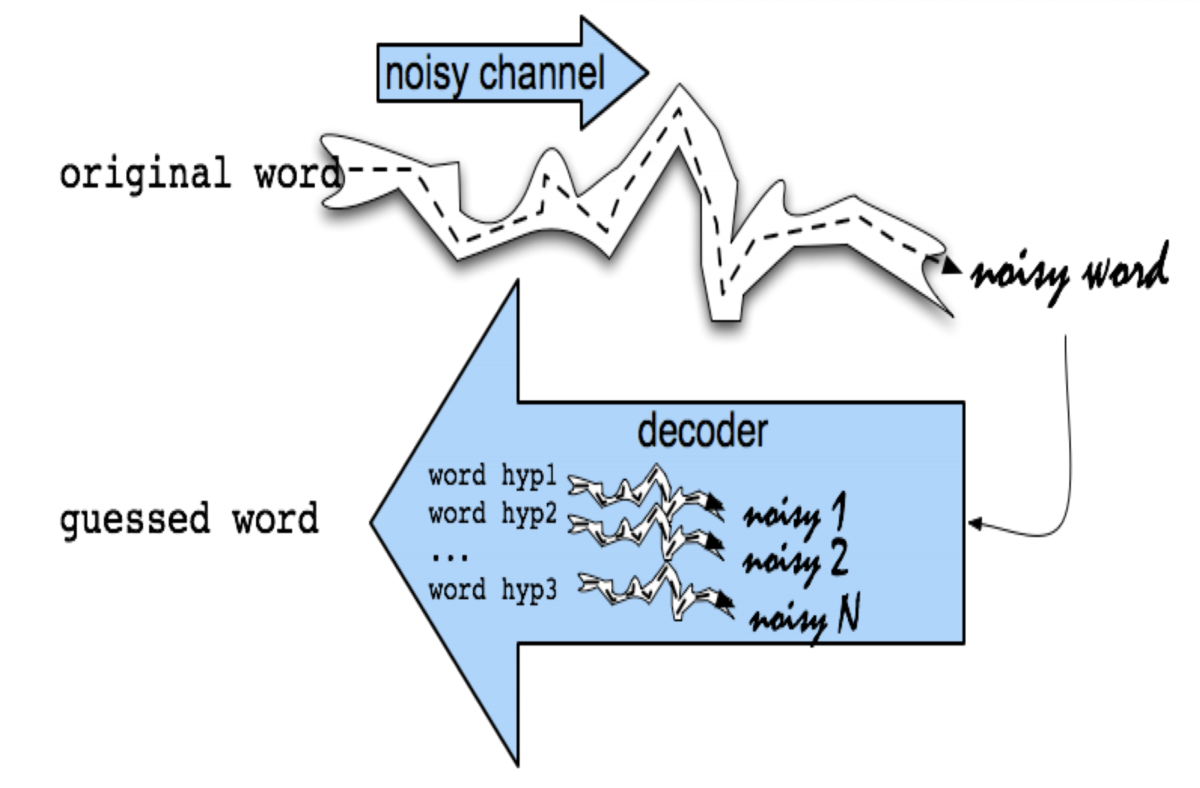
Noisy channel モデルによる文脈非依存のスペル訂正
- Noisy channel (雑音のある通信路)モデル
- 観測された単語(誤りを含む)が、元の単語に何らかの雑音が付与されたと考える
- 雑音を取り除くデコーダを構成し、それで逆変換することで、元の単語を推定することができる
- 1990 年代に提案された
- IBM
- Mays, Eric, Fred J. Damerau and Robert L. Mercer. 1991. Context based spelling correction. Information Processing and Management, 23(5), 517–522
- AT&T Bell Labs
- Kernighan, Mark D., Kenneth W. Church, and William A. Gale. 1990. A spelling correction program based on a noisy channel model. Proceedings of COLING 1990, 205-210
- IBM
- ベイズの定理を使う
- 真の単語の確率変数
- 観測された単語の確率変数
- 予測された単語
- 真の単語の確率変数
が Noisy channel モデルを表す
は単語の事前分布
- 入力ログから学習できる
- Non-word スペル誤りに対しては文脈(単語の周辺の情報)は不要
言語モデル
Noisy channel モデルの確率分布
- 編集の確率分布を表す
- 挿入、削除、置換、隣接文字交換
- 各種の誤り確率を計算するために、以下のような混合行列を計算する
del[x,y]:xyがxと入力された回数ins[x,y]:xがxyと入力された回数sub[x,y]:yがxと入力された回数trans[x,y]:xyがyxと入力された回数
- 混合行列の生成
- Noisy channel モデルの確率分布を以下のようにする
- Add-1 スムージング
- 混合行列のデータに出てこなかったスペル誤りは訂正できない
- すべてのカウントに 1 を足すスムージングを入れて、これを回避する
評価データ
- 以下のようなスペル誤りのテストセットが公開されている
- Wikipedia
- aspell
- Wikipedia のデータのフィルタされたバージョンがある
- Birkbeck spelling error corpus
- Peter Norvig
Noisy channel モデルによる文脈依存のスペル訂正
- Real-word スペル誤りに対しては文脈(単語の周辺の情報)が必要
- 文(クエリ)中の各単語について
- 候補集合を生成する
- 単語そのもの
- 1文字までの編集で辞書に入っているもの
- 異形同音異義語 (homophone)
- 候補集合を生成する
- すべての候補からもっともよいものを選択する
- Noisy channel モデルを使って計算
Real-word スペル訂正の流れ
- 候補生成
- 文
x1, x2, x3, ..., xnがあったとするxiは単語
- 各単語
xiに対して候補集合を生成Candidate(x1) = {x1, w1, w1', w1''}Candidate(x2) = {x2, w2, w2', w2''}Candidate(x3) = {x3, w3, w3', w3''}
- 文
- 候補選択
Noisy channel モデルの改良
- 重み付き Noisy channel モデル
は開発セット (development test set) から学習
- Richer edit [Brill and Moore 2000]
- ent --> ant
- ph --> f
- le --> al
- 発音を通信路のモデルに組み込む [Toutanova and Moore 2002]
- デバイスを通信路のモデルに組み込む
- 端末ごとの違いを取り入れる
- デバイスごとにシステム的に分けてもよい
講義資料
- Wildcard queries and Spelling Correction (pdf)
- Spelling correction