Information Retrieval and Web Search まとめ(2): 転置インデックス
情報検索の概要と、情報検索における基本的なデータ構造である転置インデックス、そしてその構築方法について説明する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の2日目の記事です。
情報検索とは
情報検索 (information retrieval; IR) とは、(通常コンピュータに保存されている)非構造の大規模コレクションのなかから、情報ニーズを満たす資料(通常は文書)を見つけ出すこと。
Web 検索のことを思い浮かべがちだが、以下のようなものも含まれる:
- Eメール検索
- PC内のファイル検索
- 社内ナレッジベース検索
- 法律文書の検索
情報検索における基本的な仮定
- コレクション
- 文書集合
- ゴール
- ユーザの情報ニーズに関連していて (relevant)、ユーザーがタスクを完了するのに役立つ情報を含んでいる文書を取得すること
古典的な検索モデル
- 本当のユーザタスク (user task) から情報ニーズ (information needs) が構築されるまでに誤解 (misconception) の余地がある
- 情報ニーズからクエリが構成されるまでに成形ミス (misformulation) が発生することがある
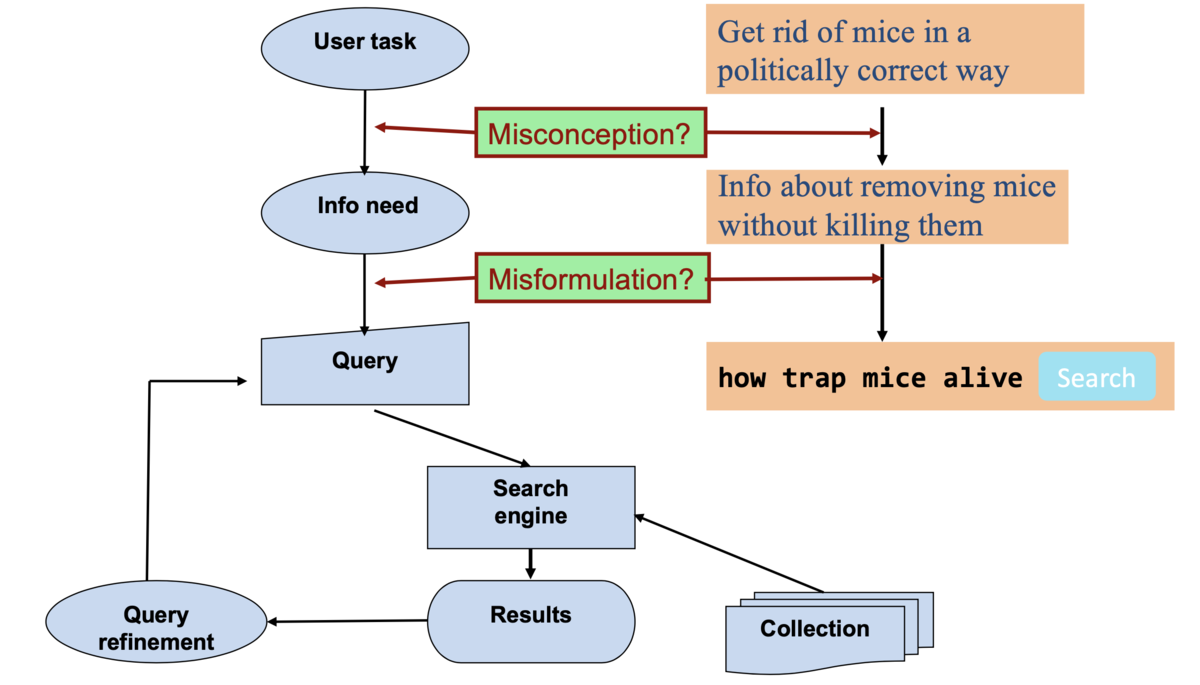
検索結果のよさ
- 適合率 (precision)
- 検索結果の文書のうち、ユーザの情報ニーズに関連しているものの割合
- 再現率 (recall)
- コレクション内に含まれる関連文書のうち、検索結果に含まれる文書の割合
より正確な定義は後に説明する。
ターム-文書接続行列
- シェイクスピアの戯曲のなかから、 "Brutus AND Caesar but NOT Calpurnia" にマッチする作品を探す
grepでも同様のことはできるが、- 遅い
- "NOT Calpurnia" に回答するのが難しい
- 例えば "Romans near countrymen" のようなクエリに回答できない
- ランク付けができない
- ターム-文書接続行列 (term-document incidence matrices) を定義する
- 行列の要素
(t, d)は、列dの文書のなかに、行tの単語が含まれていれば 1、そうでなければ 0 - これはタームと文書間のハイパーグラフになる
- 行列の要素
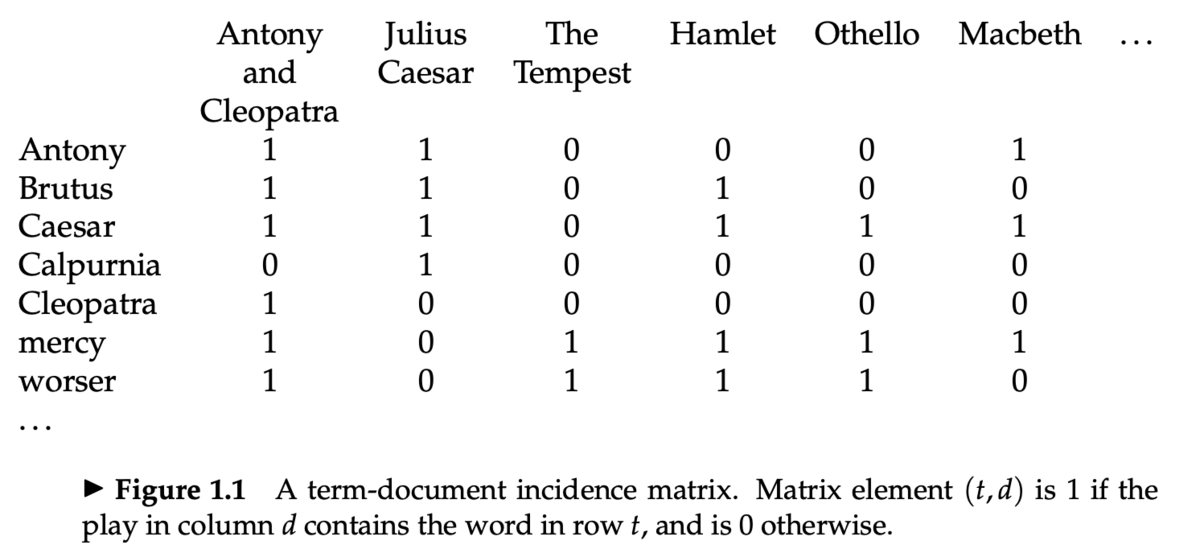
- この行列の上でビット演算をすることで、クエリに答えることができる
- しかし、大規模なコレクションではメモリを大量に消費する
- 要素はほとんど 0、つまりスパース
転置インデックス
- 各ターム
tごとに、tを含んでいる文書のリストだけを持てばよい- 文書は連続する番号、文書 ID (docID) をつけて識別する
- この文書のリスト(配列)のことをポスティングリスト (postings list) と呼ぶ
- これに含まれる1つ1つの文書(ID)のことをポスティング (posting) という
- ポスティングリストは文書 ID の順番でソートしておく
- 理由は後ほど説明する
- タームの集合のことを辞書 (Dictionary) と呼ぶ

転置インデックスの構築
転置インデックスは以下のステップで構築される。
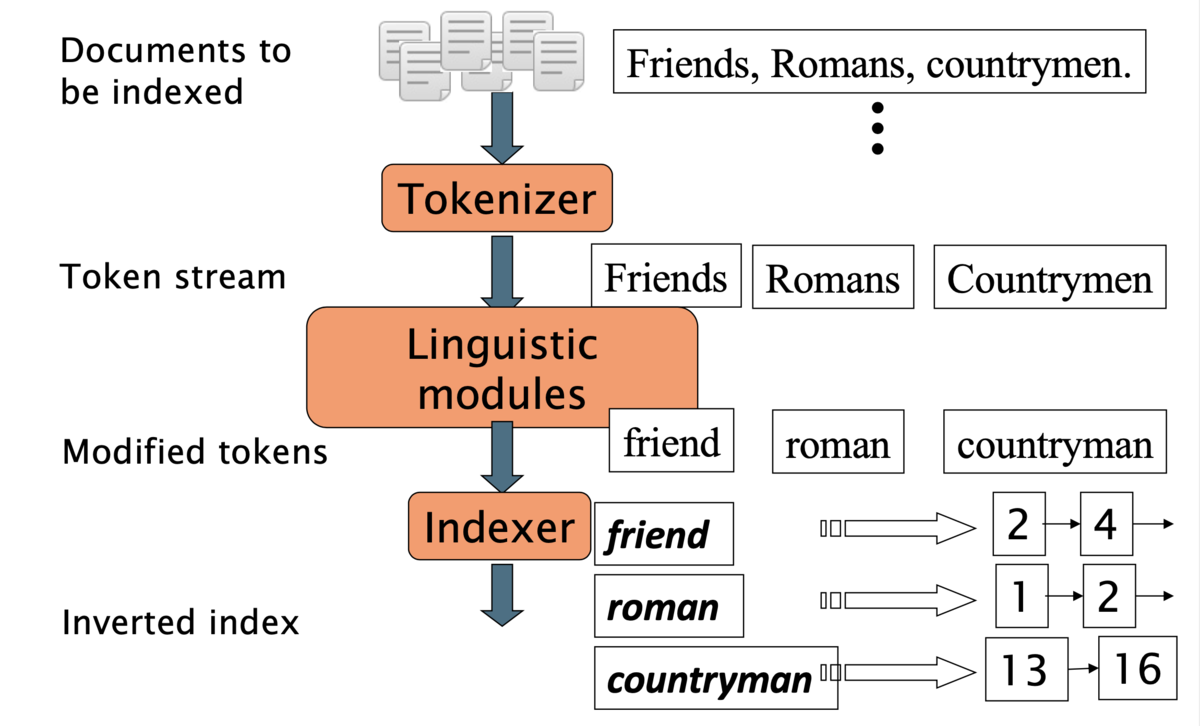
- トークナイズ (tokenizatiion)
- 文字列を単語トークン (token) に分割する
- 正規化 (normalization)
- 文書テキストもしくはクエリに含まれるトークンを同じ形式に揃える
- 例: "U.S.A." --> "USA"
- ステミング (stemming)
- 語幹のみの形に揃える
- ストップワード (stop word) の除去
- 頻出語、もしくはほとんど出現しない単語を除去する
- 例: "the", "a", "to", "of"
2つの文書 (Doc 1, Doc 2) からなるコレクションの転置インデックスを構築する例:

- 各文書のテキストをタームに分割し、そのタームに文書 ID をつけた
(token, docID)のペアにする(左) - タームの辞書順でソートする(中央)
- 辞書とポスティングリストを構築する
- 辞書にはターム自体とポスティングリストへのポインタが含まれる
- また、辞書の各項目にはポスティングリストの長さ(=文書頻度)などの統計情報も含める(後ほど出てくるクエリ処理の高速化に使う)
- ポスティングリストには文書 ID のリストと、追加の情報が含まれる
- 文書中に現れるそのタームの登場回数(=ターム頻度)やそのポジションなど
- こちらもなぜ必要になるかは後ほど説明する
トークナイズ(分かち書き)
- 文字列の並びをトークンに分割
- 入力
- "Friends, Romans and Countrymen"
- 出力
- Friends
- Romans
- Countrymen
- トークンは、インデックスのエントリの候補となる(後ほど説明)
トークナイズにおける問題
- トークンの単位
- "Finland's capital" --> "Finland + s" or "Finlands" or "Finland's"?
- "Hewlett-Packard" --> "Hewlett" + "Packard" に分割する?
- "San Francisco" --> 同上
- "state-of-the-art" --> ハイフンで分割する?
- "co-education" --> 同上
- 数値
- 言語の違い
- フランス語
- "L'ensemble" --> 分割する?
- "L" or "L'" or "Le"?
- "L'ensemble" は "un ensemble" でマッチしてほしい
- 少なくとも 2003年まで Google ではできなかった
- "L'ensemble" --> 分割する?
- ドイツ語
- "Lebensversicherungsgesellschaftsangestellter"
- "life insurance company employee" という意味
- 非常に長い複合語
- 複合語分割モジュールを利用すると性能が向上
- "Lebensversicherungsgesellschaftsangestellter"
- 中国語、日本語
- "莎拉波娃现在居住在美国东南部的佛罗里达"
- 単語と単語のあいだにスペースがない
- トークナイズの揺れが発生しうる
- "フォーチュン500社は情報不足のため時間あたり$500K(約6,000万円)"
- 日本語の文には複数の字種が混在
- ユーザはひらがなで検索することもある
- "莎拉波娃现在居住在美国东南部的佛罗里达"
- アラビア語、ヘブライ語
- 右から左に書かれる
- 単語はスペースで分割されているが、複雑な合字がある
- フランス語
ストップワード
- 頻出する単語をストップワードのリスト (stop list) を使って除外できる
- "the", "a", "and", "to", "be"
- 最頻出トップ 30 単語で ~30% のポスティングを占める(英語の場合)
- だが、最近はこれを行わない
正規化
- タームへの正規化
- ターム (term) とは、正規化された単語のタイプであり、検索システム内の辞書のエントリに対応する
- 以下のような、等価なクラスがある
- ピリオドの削除
- 例:"U.S.A." --> "USA"
- ハイフンの削除
- 例:"anti-discriminatory" --> "antidiscriminatory"
- ピリオドの削除
- アクセント記号
- 例:"résumé" と "resume"(フランス語)
- ウムラウト
- 例:"Tuebingen" と "Tübingen"(ドイツ語)
- 正規化の基準
- 「ユーザはこれらの単語のクエリをどのように書くか?」
- アクセントがある言語のユーザでも、アクセントを入力しないことが多い
- アクセントを外すように正規化するのが好ましい
- 日付のフォーマット
- "7月30日" と "7/30"(日本語)
- トークナイズと正規化は言語に依存する
- "Morgen will ich in MIT ..."
- "MIT" はドイツ語の "mit"?
- "Morgen will ich in MIT ..."
- 大文字・小文字
- 非対称なクエリ展開
- シソーラス(類語)
- シノニムと同音異義語
- "car" = "automobile"
- 完全に同一のクラスとしてしまう方法
- どちらも "car-automobile" としてインデックスする
- クエリ拡張する方法
- "automobile" で検索されたとき、 "car" でも検索する
- スペル訂正
- 1つのアプローチとして Soundex がある
- 発音のヒューリスティクスに基づいて作成された辞書
- 1つのアプローチとして Soundex がある
レンマ化
- レンマ化 (lemmatization) は、活用形 (inflectional/variant form) を基本形にする処理
- 例
- "am", "are", "is" --> "be"
- "car", "cars", "car's", "cars'" --> "car"
- "the boy's cars are different colors" --> "the boy car be different color"
- 辞書の見出し語への変形のようなもの
ステミング
- 単語の語幹を取り出す
- 言語に依存する
- 例
- "automate(s)", "automatic", "automation"
- --> "automat"
- "for example compressed and compression are both accepted as equivalent to compress."
- --> "for exampl compress and compress ar both accept as equival to compress"
- "automate(s)", "automatic", "automation"
- ポーターのアルゴリズム (Porter's algorithm)
- 英語をステミングするときの代表的なアルゴリズム
- Porter's stemmer や Porter stemming algorithm とも
- ルール
- "sses" --> "ss"
- "ies" --> "i"
- "ational" --> "ate"
- "tional" --> "tion"
- 文字数によって変化するルールも
(m>1)EMENT -->- "replacement" --> "replac"
- "cement" --> "cement"
- 他のステマー
- Lovins stemmer
- Paice/Husk stemmer
- Snowball
- 形態素解析によるレンマ化
- それほど効果はない(英語)
- ステミングの効果
講義資料
- Inverted Indices (pdf)
- Document Encodings (pptx)
- Tokens (pptx)
- Terms (pptx)
- Stemming (pptx)
- Skip Lists (pptx)
参考資料
- IIR chapter 1
- IIR chapter 2
- MG sections 3.6, 4.3
- MIR section 7.2
- Porter's stemmer (MIR)
- Porter stemming algorithm (Official)
- A skip list cookbook (Pugh 1990)
- Fast phrase querying with combined indexes (Williams, Zobel, Bahle 2004)
- Efficient phrase querying with an auxiliary index (Bahle, Williams, Zobel 2002)