Information Retrieval and Web Search まとめ(11): スコア計算:TF-IDFとベクトル空間モデル
前回は、Noisy channel モデルによるクエリのスペル訂正について説明した。今回は、文書のスコアリングとそのモデルについて書く。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の11日目の記事です。
ランク付き検索
ブーリアン検索の問題点
- ここまでは単なるブーリアンクエリを扱ってきた
- 文書がマッチするかどうかだけ見ていた
- 情報ニーズやコレクションに関して深く理解しているエキスパートユーザにとっては十分
- アプリケーションにもよる
- だが、ほとんどのユーザにとっては適切ではない
- ほとんどのユーザはブーリアンクエリを組み立てられない(もしくはできても面倒)
- 数千件もある検索結果を全部見ていきたくない
- とくに Web 検索では検索結果が多い
- ブーリアンクエリの検索結果は、しばしば非常に少なくなる(=0)か、非常に多くなる(>1000)
- "standard user dlink 650" --> 200,000 件
- "standard user dlink 650 no card found" --> 0 件
- 適切な件数の検索結果を得るにはスキルが必要
ランク付き検索モデル
- ランク付き検索 (ranked retrieval) では、クエリに対して、コレクション内の上位の文書を順序付きで返す
- クエリは演算子(AND, OR, NOT など)や式ではなく、単語から構成されるフリーテキストで書かれることもある
- ランク付きの検索結果が得られれば、検索結果が膨大になっても問題にならない
- ユーザは上位 k (~ 10) 件の結果を見る
- ただし、ランキングアルゴリズムが有効に働いているという仮定のもと
- スコアリングがランク付き検索の基礎
- ユーザにとって有用と思われる文書を順番に返したい
- クエリに対して文書をどうやって順序付けすればよいか
- 各文書にスコア(たとえば
[0, 1]の範囲で)をつける - このスコアがクエリと文書がどのくらい「適合 (match)」しているかを表す
- 各文書にスコア(たとえば
文書のスコア計算
Bag of words モデル
- Bag of words モデル は、タームの出現回数を考慮する文書のモデル
- ただし、単語の出現した順番は考慮しない
- 以下の2つは Bag of words モデルでは同じになる
- "John is quicker than Mary"
- "Mary is quicker than John"
- 位置インデックスではこれらの2つを区別できたが、Bag of words モデルではできない
- ただし、単語の出現した順番は考慮しない
- 以下の議論では、文書もクエリもこの Bag of words モデルを基本とする
クエリと文書の適合度
- クエリと文書のペアに対してスコアを付けたい
- 1タームのクエリで考える
- もし、文書中にそのタームがなければ、スコアは 0(古典的には)
- 文書中にたくさんそのタームが出現していれば、そのぶんスコアは高くなる(べき)
Jaccard 係数
- Jaccard 係数 (Jaccard coefficient) は、集合どうしの重なり(共通部分)の代表的な指標
- 集合 A, B に対して以下のように定義される
- A と B の要素数は同じでなくてもよい
- Jaccard 係数は 0 から 1 の間の値を取る
- 集合 A, B に対して以下のように定義される
- 文書とクエリそれぞれについて、それぞれが含むタームを要素とする集合と考え、各ペアの Jaccard 係数を計算することができる
- それによってクエリ-文書ペアをスコアリングする
- Jaccard 係数の問題点
- 文書中のターム頻度 (term frequency; TF) (文書中にタームが出現する回数)を考慮していない(ターム頻度については後述する)
- あまり出現しない単語は、頻出語よりも情報量が多いはずだが、Jaccard 係数はこれを考慮に入れない
- 長さの正規化に関してもっと賢い方法が必要
タームの重み付け
ターム-文書カウント行列
- Information Retrieval and Web Search まとめ(2): 転置インデックスで説明した、ターム-文書接続行列 (term-document incidence matrices) を思い出す
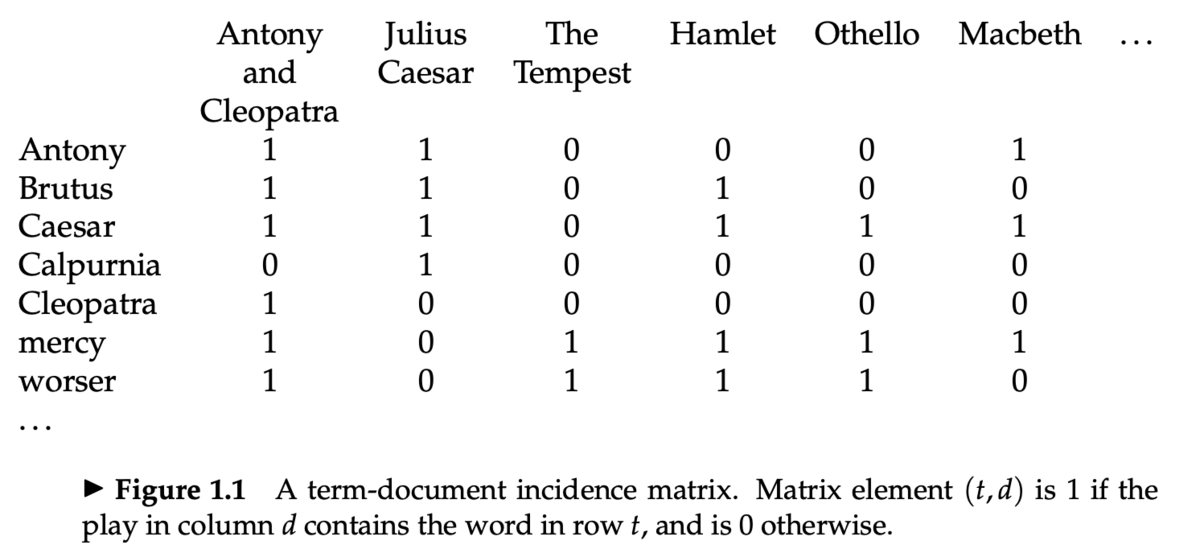
- 各文書(この行列の列にあらわれている作品)は、2値ベクトル
で表現される
- 次に、この行列の要素を、タームの出現回数で置き換える
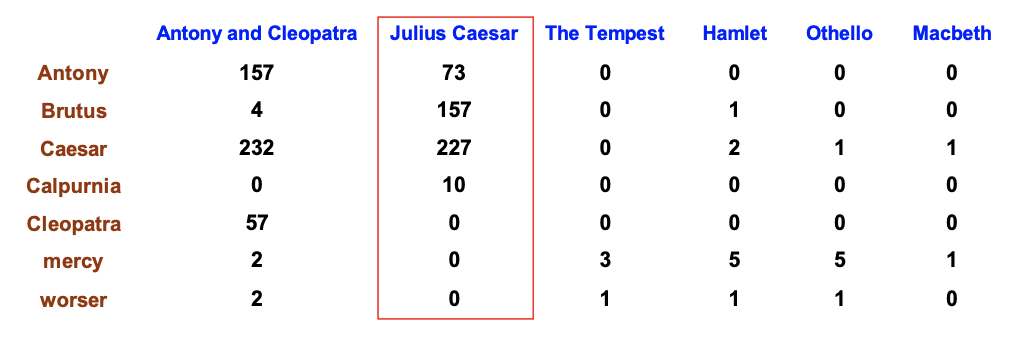
- 各文書は、カウントベクトル
で表現される
ターム頻度 (TF)
- ターム頻度 (term frequency; TF)
は、文書
内のターム
に対して定義され、
- この tf をクエリと文書の適合スコアを計算するのに使いたい
- だが、tf そのものは求めているものではない
- タームが 10 回出現する文書は 1 回出現する文書より適合していると考えられる
- だが、10倍も適合しているわけではない
- 適合度は tf に線形に増えるわけではない
- 対数頻度重み付け (log-frequency weighting) により、この問題を緩和する
- tf と、対数頻度重み付けした tf は以下のようになる
- 0 --> 0
- 1 --> 1
- 2 --> 1.3
- 10 --> 2
- 1000 --> 4
- 文書-クエリペアのスコアリング
- クエリ
と文書
- 文書中にクエリ内のタームがひとつも出現していなかった場合、スコアは 0
- クエリ
コレクションの統計情報
- レアなタームは頻出するタームよりもより有用 (informative) であるはず
- 例: arachnocentric のような単語
- そこで、コレクションの中での希少度を考慮に入れる
- レアなタームにはより大きい重み付けをする
- コレクション頻度 (collection frequency) cf は、コレクション中にターム t が出現する回数
- 文書頻度 (document frequency) df は、ターム t を含む文書の数

逆文書頻度 (IDF)
- ターム t の逆文書頻度 (inverse document frequency) idf を以下のように定義する
- idf の効果をなめらかにする (dampen) ために log をとる
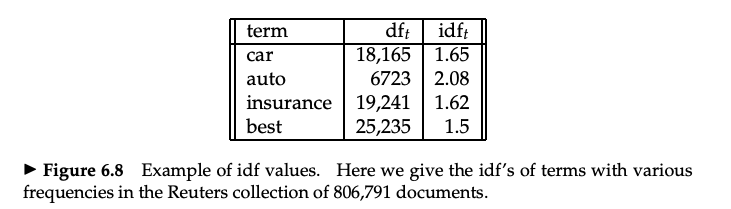

- ランキングにおける idf の効果
- 1タームのクエリに対しては idf は効果をもたない
capricious personというクエリがあったとき、idf はpersonよりもcapriciousに大きい重みを与える
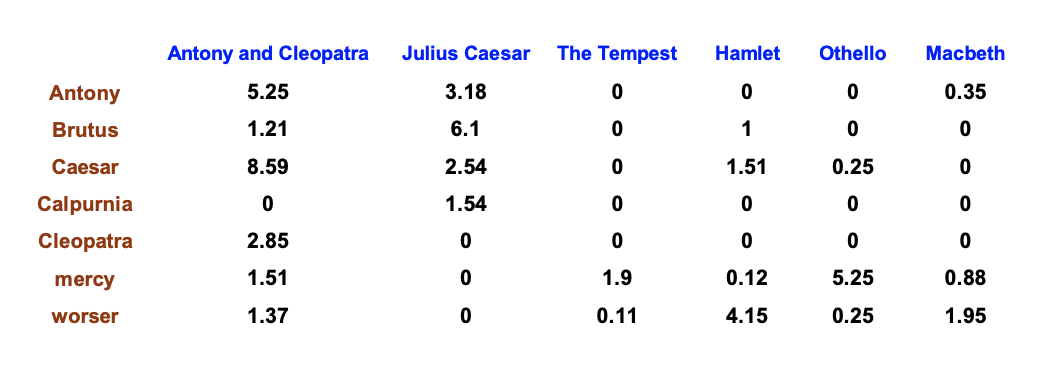
TF-IDF 重み付け
- TF-IDF 重み付けは、以下のように tf と idf の積によって重みを定義する
- TF-IDF は、情報検索において最もよく知られている重み付けの1つ
- 他に有名なものとしては BM25 がある(後日紹介)
- 文書中のタームの出現回数が多いと大きくなる
- コレクション中のタームの希少度が高いと大きくなる
- クエリ q が与えられたときの文書 d のスコアは以下のように計算する
- TF-IDF によってターム-文書カウント行列は、以下のようなターム-文書重み行列となる
- 各文書は、重みベクトル
で表現される
ベクトル空間モデル
文書ベクトル
- ここまで、文書をベクトル
として表現してきた
- |V| 次元のベクトル空間を考える
- 文書はこの空間での点、もしくはベクトルとなる
- タームはこの空間の軸となる
- この空間は非常に高次元になる
- たとえば Web 検索では、数千万次元になる
- また、このベクトルは非常に疎
- ほとんどの要素は 0
クエリベクトル
- クエリについても、空間内のベクトルとして表現する
- この空間において、クエリベクトルへの「近さ (proximity)」に応じて文書をランク付けする
コサイン類似度
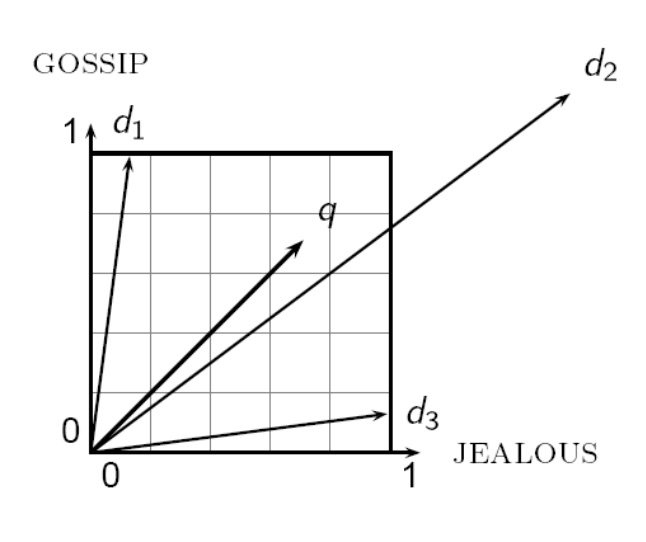
- 距離ではなく、角度 (angle) はどうか?
- 文書 d にそれ自身の単語をすべて足した文書 d' を考える
- 意味的には d と d' は同じものであると考えられるが、ユークリッド距離上は非常に離れたものになる
- d と d' のベクトル同士がなす角度 (angle) は 0
- クエリとの角度の大きさによって文書をランク付けするとよさそう
- 角度ではなく、コサインを使う
- 以下の2つは同じ
- 「クエリと文書の角度の降順で、文書をランク付けする」
- 「
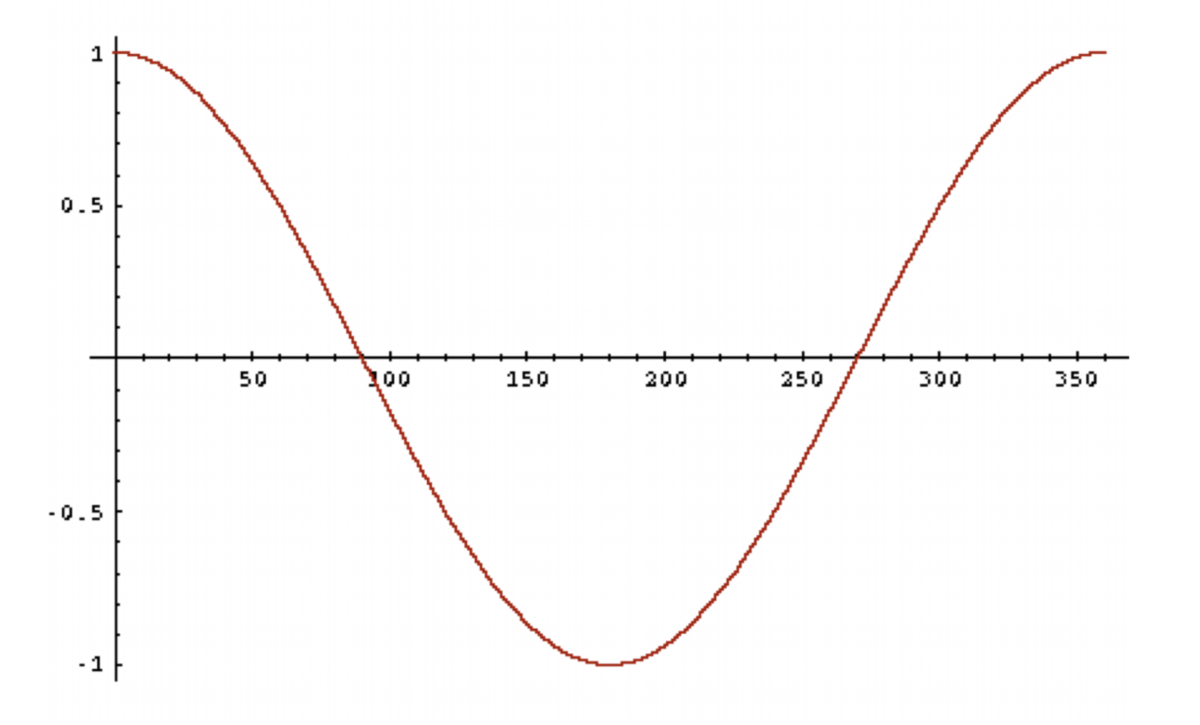
cosine(query, document)の昇順で、文書をランク付けする」 - コサイン関数は
] の区間で単調減少、かつ
] (0° のとき 1、180° のとき -1)の値を取るので、類似度の指標として都合が良い
文書長の正規化
- ベクトルは各成分をその長さで割ることで正規化できる
- 正規化には
ノルムを使う:
- ベクトルをその
- 単位ベクトルは全て半径 1 の単位超球上の点になる
- この正規化により、上記の文書 d と d' (d の単語を2倍にした文書)は同じベクトルになる
- また、長い文書と短い文書も比較しやすくなる
- 文書長による影響を減らすことができる
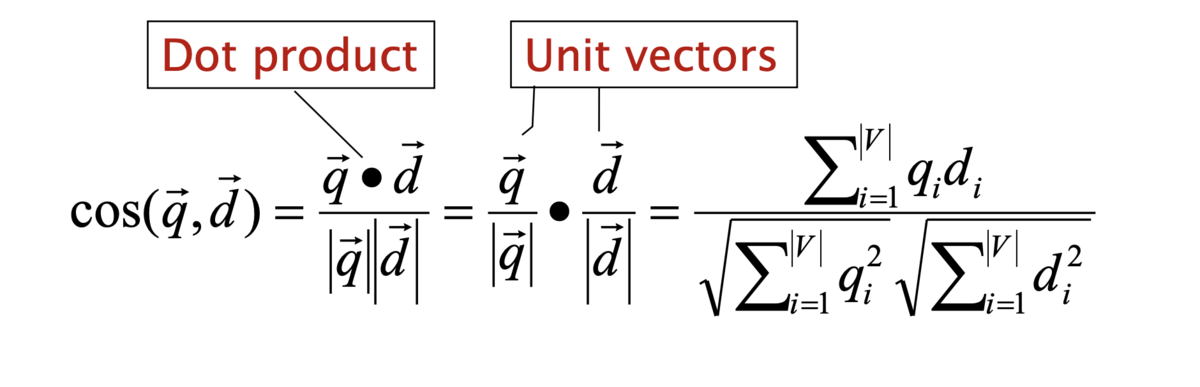
コサイン類似度の計算
- クエリベクトル
と文書ベクトル
のコサインの計算は以下のようになる
は
ベクトル空間モデルによるスコア計算

- このアルゴリズムは term-at-a-time (TAAT)
- タームごとにスコア計算していく方式
- document-at-a-time (DAAT) にすることもできる
- ポスティングごとに重み
を事前に計算してポスティングリストに保存しておくこともできるがもったいない
- 浮動小数点数なので大きい
- TF-IDF の場合、
(ターム t の逆文書頻度)はポスティングリストの先頭に保存する
- (動的に重み付けを変えることもできる)
- Top-k のアイテムは優先度付きキュー(たとえばヒープ)を使えば高速に抽出できる
TF-IDF のバリエーション
- TF-IDF には、他にも様々な亜種 (variant) がある

- クエリと文書それぞれでタームの重み付けを変えることもできる
- 標準的な重み付けの方法は
- 文書
- ターム頻度 (TF):
logarithm - 文書頻度 (DF):
no idf - 正規化:
cosine
- ターム頻度 (TF):
- クエリ
- ターム頻度 (TF):
logarithm - 文書頻度 (DF):
idf - 正規化:
cosine
- ターム頻度 (TF):
- 文書
講義資料
参考資料
- IIR chapter 6
- 6.2-6.4.3
- Cosine Similarity Tutorial
Information Retrieval and Web Search まとめ(10): スペル訂正
前回は、Permuterm インデックスや k-gram インデックスを使ったワイルドカード検索について解説した。今回は、クエリのスペル訂正を扱う。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の10日目の記事です。
スペル訂正
- スペル訂正の応用
- 文書作成 (MS Word, Google Docs, ...)
- 携帯電話での入力
- Web 検索
- スペルミスの頻度
- アプリケーションによるが、 ~1-20%
- 26%: Webクエリ [Wang et al. 2003]
- 13%: バックスペースなしでのリタイプ(英語とドイツ語) [Whiteelaw et al.]
- 7%: 携帯電話サイズのハンドヘルドで、単語がリタイプで修正されたとき [Soukoreff & MacKenzie 2003]
- 2%: 携帯電話サイズのハンドヘルドで、単語が修正されなかったとき [Soukoreff & MacKenzie 2003]
- 1-2%: リタイプ [Kane and Wobbrock 2007, Gruden et al. 1983]
スペル訂正のタスク
- スペル誤りの検知
- スペル誤りの訂正
- オートコレクト (
hte-->the) - スペル候補のサジェスト
- サジェストリスト
- オートコレクト (
スペル誤りのタイプ
- Non-word(単語ではない)エラー
graffe-->giraffe- Non-word エラーは歴史的には文脈に依存しないものだった
- (古典的には)文脈に依存しない
- Real-word(実単語の)エラー
- タイポエラー
three-->there
- 認識エラー(異形同音異義語 (homophone))
piece-->peacetoo-->twoyour-->you're
- Real-word エラーはほとんど文脈に合わせて訂正する必要がある
- タイポエラー
Non-word スペル誤り
- Non-word スペル誤りの検知
- 辞書に入っていない単語はエラーとする
- (ある一定までは)辞書を大きくすると改善される
- Web 検索ではスペルミスが非常に多いので、大きい辞書の必要性は低い
- Non-word スペル誤りの訂正
- 候補生成
- 元の入力と似ている実単語を候補とする
- もっとも良い候補を選択
- 重み付き編集距離 (weighted edit distance) が最短のもの
- 雑音のある通信路 (noisy channel) での確率が最も高いもの
- 候補生成
Real-word スペル誤り
- 各単語
wについて、候補集合を生成する- 発音が似ているもの
- スペルが似ているもの
wも候補に含める
- 最もよい候補を選択
- 雑音のある通信路でスペル誤りを評価
- 文脈依存
- "Flying form Heathrow to LAX" --> "Flying from Heathrow to LAX"
候補生成
- 以下の基準で候補となる単語を列挙する
- 似ているスペルの単語
- 編集距離が小さいもの
- 似ている発音の単語
- 発音の距離が小さいもの
- 似ているスペルの単語
- 80% の誤りは編集距離 1 まで
- 編集距離 2 まででほとんどの誤りがカバーできる
- 以下のような方法で候補生成ができる
Damerau-Levenshtein 編集距離
- Damerau-Levenshtein 編集距離 (Damerau-Levenshtein edit distance) は、2つの文字列の編集距離を測る尺度の1つ
- 文字の編集
- 挿入
- 削除
- 置換
- 隣接文字交換
- これ以外は Levenshtein 編集距離と同じ
- 編集距離については IIR 3.3.3 節を参照
Noisy channel モデルによる文脈非依存のスペル訂正
- Noisy channel (雑音のある通信路)モデル
- 観測された単語(誤りを含む)が、元の単語に何らかの雑音が付与されたと考える
- 雑音を取り除くデコーダを構成し、それで逆変換することで、元の単語を推定することができる
- 1990 年代に提案された
- IBM
- Mays, Eric, Fred J. Damerau and Robert L. Mercer. 1991. Context based spelling correction. Information Processing and Management, 23(5), 517–522
- AT&T Bell Labs
- Kernighan, Mark D., Kenneth W. Church, and William A. Gale. 1990. A spelling correction program based on a noisy channel model. Proceedings of COLING 1990, 205-210
- IBM
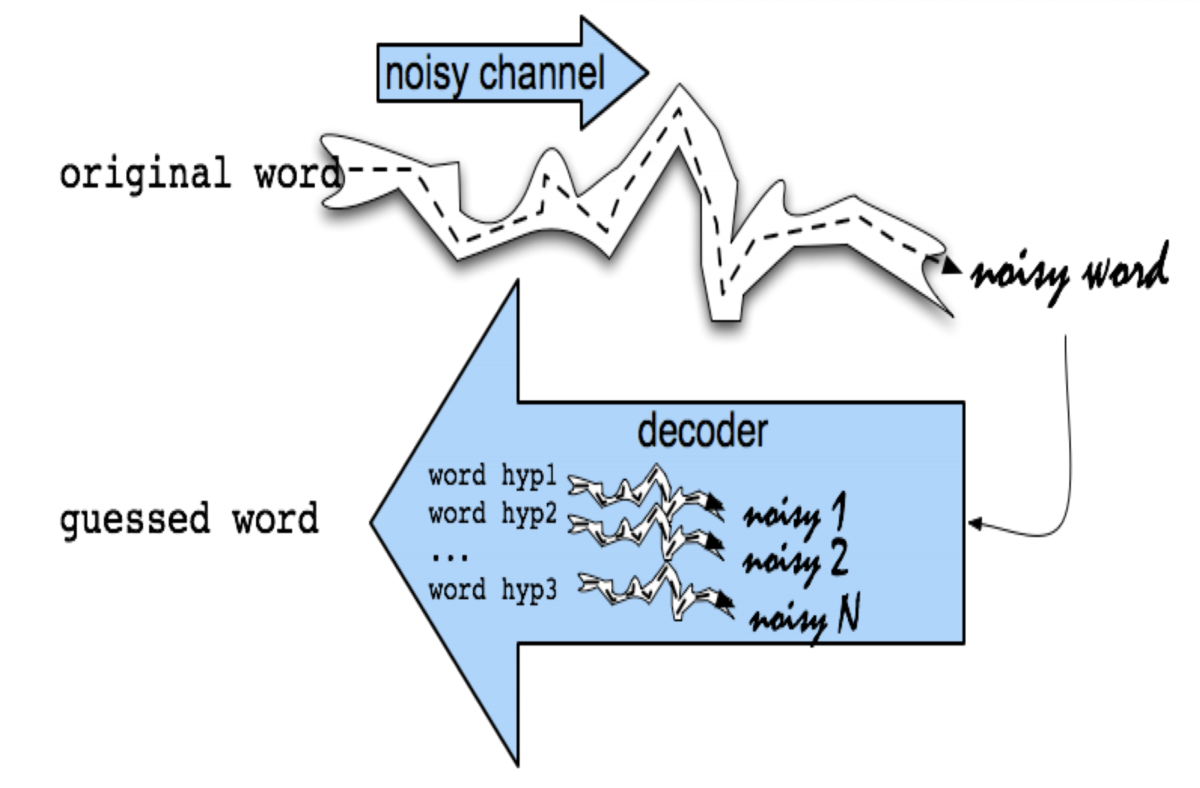
- ベイズの定理を使う
- 真の単語の確率変数
- 観測された単語の確率変数
- 予測された単語
- 真の単語の確率変数
が Noisy channel モデルを表す
は単語の事前分布
- 入力ログから学習できる
- Non-word スペル誤りに対しては文脈(単語の周辺の情報)は不要
言語モデル
Noisy channel モデルの確率分布
- 編集の確率分布を表す
- 挿入、削除、置換、隣接文字交換
- 各種の誤り確率を計算するために、以下のような混合行列を計算する
del[x,y]:xyがxと入力された回数ins[x,y]:xがxyと入力された回数sub[x,y]:yがxと入力された回数trans[x,y]:xyがyxと入力された回数
- 混合行列の生成
- Noisy channel モデルの確率分布を以下のようにする
- Add-1 スムージング
- 混合行列のデータに出てこなかったスペル誤りは訂正できない
- すべてのカウントに 1 を足すスムージングを入れて、これを回避する
評価データ
- 以下のようなスペル誤りのテストセットが公開されている
- Wikipedia
- aspell
- Wikipedia のデータのフィルタされたバージョンがある
- Birkbeck spelling error corpus
- Peter Norvig
Noisy channel モデルによる文脈依存のスペル訂正
- Real-word スペル誤りに対しては文脈(単語の周辺の情報)が必要
- 文(クエリ)中の各単語について
- 候補集合を生成する
- 単語そのもの
- 1文字までの編集で辞書に入っているもの
- 異形同音異義語 (homophone)
- 候補集合を生成する
- すべての候補からもっともよいものを選択する
- Noisy channel モデルを使って計算
Real-word スペル訂正の流れ
- 候補生成
- 文
x1, x2, x3, ..., xnがあったとするxiは単語
- 各単語
xiに対して候補集合を生成Candidate(x1) = {x1, w1, w1', w1''}Candidate(x2) = {x2, w2, w2', w2''}Candidate(x3) = {x3, w3, w3', w3''}
- 文
- 候補選択
Noisy channel モデルの改良
- 重み付き Noisy channel モデル
は開発セット (development test set) から学習
- Richer edit [Brill and Moore 2000]
- ent --> ant
- ph --> f
- le --> al
- 発音を通信路のモデルに組み込む [Toutanova and Moore 2002]
- デバイスを通信路のモデルに組み込む
- 端末ごとの違いを取り入れる
- デバイスごとにシステム的に分けてもよい
講義資料
- Wildcard queries and Spelling Correction (pdf)
- Spelling correction
参考資料
Information Retrieval and Web Search まとめ(9): ワイルドカード検索
前回は、ポスティングリストの圧縮のための様々な符号化について説明した。今回はワイルドカード検索についてまとめる。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の9日目の記事です。
ワイルドカードクエリ
- ワイルドカードクエリ (wild-card query) は、ワイルドカードを表す
*をもつクエリmon*: "mon" で始まるすべてのタームで検索する- 二分探索木 (binary search tree)、もしくは B木 (B-tree) で実装できる:
mon <= w < mooであるような全てのタームwを取得すればよい
*mon: "mon" で終わるすべてのタームで検索する- タームの逆順 (backwards) で構築した B 木が必要
nom <= w < nonであるような全てのタームwを取得する
pro*centのようなワイルドカードクエリは?

ワイルドカードクエリのクエリ処理
- ワイルドカードクエリに合致するすべてのタームを列挙する
- 列挙された各タームに対して、ポスティングを検索する
- 大量の AND 検索が行われる可能性がある
- 例:
se*ate AND fil*er
- 例:
Permuterm インデックス
co*tionのようなタームの中間に*があるクエリ- B木を使って
co* AND *tionとして検索できる- このようなクエリは高価
- アイデア:ワイルドカードクエリを
*が最後に来るように変換する - Permuterm インデックス
$を各タームの最後に追加する- その文字列を1文字回転させて B木にインデックスするのを繰り返す
- 例:
hello-->hello$,ello$h,llo$he,lo$hel,$hello
- 例:
- 経験的には、辞書のサイズは 4 倍になる

Permuterm クエリ処理
- Permuterm インデックスでのクエリ処理の方法
- 入力されたクエリに
$をつけ、*が(あれば)最後に来るように回転させる - 入力クエリ
X-->X$で検索hello-->hello$
- 入力クエリ
X*-->$X*で検索hel*-->$hel*
- 入力クエリ
*X-->X$*で検索*llo-->llo$*
- 入力クエリ
*X*-->X*で検索*ell*-->ell*
- 入力クエリ
X*Y-->Y$X*で検索h*lo-->lo$h*
- 入力クエリ
X*Y*Z-->X*Zで検索したあとフィルタするh*a*o-->h*o-->o$h*で検索 -->h*a*oにマッチしないタームをフィルタ
k-gram インデックス
- すべてのタームのすべての k-gram を列挙する
- 例: "april" の 2-gram (bi-gram) は以下のようになる
$a,ap,pr,ri,il,l$
- 例: "april" の 2-gram (bi-gram) は以下のようになる
- それらの k-gram からタームへの転置インデックスを作る
- ポスティングリストとは別のもの
- k-gram で引くと、それにマッチするすべてのタームが取れるようになる
- 複数のタームがある場合、タームは辞書順で並べる

講義資料
- Wildcard queries and Spelling Correction (pdf)
- Wild-card queries
参考資料
- IIR chapter 3
- MG section 4.2
Information Retrieval and Web Search まとめ(8): ポスティングリストの圧縮
前回は、検索インデックスで使用する辞書の圧縮について扱った。今回は、ポスティングリストの圧縮について解説する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の8日目の記事です。
ポスティングリストの圧縮
- ポスティングファイル(ポスティングリストが収められたファイル)は辞書よりも少なくとも10倍、しばしば100倍以上大きい
- ポスティングの docID を小さくする
- Reuters-RCV1 (80 万文書) では docID に 32 ビット(4バイト)の整数値を使った
ビットまでは普通に小さくできる
- docID を 20 ビットよりも小さくするのが今回のゴール
- ほとんどの文書に登場するような単語 ("the" など) はもっと小さくしたい
差分符号化
- ポスティングリストでは docID を昇順で保存する
- 例:
computer: 33, 47, 154, 159, 202, ...
- 例:
- docID の差分 (gap) だけを保存すれば十分
33, 14, 107, 5, 43, ...
- ほとんどの差分は 20 ビットよりも小さく保存できるはず
- とくによく出てくる単語は

可変長符号化
- "arachnocentric" のようなレアな単語のポスティングリストには ~20 bits/gap 使ってもよい
- "the" のような単語には ~1 bit/gap にしたい
- それぞれの差分 (gap) について、できるだけ少ないビットで符号化したい
- 可変長符号化 (variable length encoding) が必要
- 可変長符号化では、小さい数字に対して小さなコードにできる
単進符号
- 単進符号 (unary code) は、数
nを、連続したn個の1と、最後の 1 つの0で表現する31110
4011111111111111111111111111111111111111110
P(n) = 2^(-n)のときには最適- 普通のユースケースではあまり有用ではない
ガンマ符号
- ガンマ符号 (γ code) は、差分 (gap)
Gを、 length と offset のペアで表現する - offset は
Gを2進数にしたあと、先頭の1を削ったもの13-->1101(2進数) -->101
- length は offset の長さを単進符号でエンコードしたもの
13 (offset 101)の length は3-->1110
- ガンマ符号は length と offset を繋げたもの
13のガンマ符号は1110101

ガンマ符号の特徴
Gはビットでエンコードされる
- offset は
ビット
- length は
ビット
- offset は
- ガンマ符号は奇数個のビットからなる
- あらゆる分布の数値で使える
P(n) ~ 1/(2n^2)のとき最適
- ガンマ符号はパラメータがない
ガンマ符号の速度
- コンピュータはワード境界をもつ(8, 16, 32, 64ビット)
- ワード境界をまたぐ操作は遅い
- ビット単位での操作はとても遅い
- 現代的な方法は、バイトやワードにアライン (align) した符号化を使っている
- 可変バイトエンコード(後述)のほうが高速
Variable-Byte (VB) 符号
- Variable-Byte (VB) 符号 は、差分 (gap)
Gを、バイト単位で符号化していく- 7ビットのデータと、1ビットの継続ビット (continuation bit)
cの並び(最上位ビットが継続ビットc) - (継続ビットと言っているが、実際には最後のバイトのときだけこのビットが
1になるので、ストップビットと言ったほうが意味的には通る気がする)
- 7ビットのデータと、1ビットの継続ビット (continuation bit)
Gが 127 以下なら、7ビット以下で表現できるので、その7ビットに継続ビットc = 1をセットして終わり- そうでないなら、
Gの低位の 7 ビットをエンコードしたあと、高位のビットは同じアルゴリズムでエンコードする- 最後のバイトの継続ビットは
1 (c = 1) - それ以外の継続ビットは
0 (c = 0)
- 最後のバイトの継続ビットは

Group Variable Integer 符号
- Google で使用されていた符号化方式
- Jeff Dean, keynote at WSDM 2009 and presentations at CS276
- 5 ~ 17 バイトのブロック内に 4 つの整数値を符号化
- 先頭バイト
- 4 つの 2ビットの長さを入れる
L1 L2 L3 L4, それぞれ 1, 2, 3, 4 のいずれかの数値が入る- それぞれが、あとに続く4つの整数値のバイト長を表現している
- そのあと、
L1 + L2 + L3 + L4バイト(4 ~ 16 バイトの範囲)の4つの数値をエンコード- それぞれの数値は 8/16/24/32 ビット(1 ~ 4 バイト)
- VB 符号より2倍ほど速いらしい
- ビットマスクの操作が不要なのでデコードが速い
Simple-9

- Simple-9 [Anh & Moffat, 2004] は、ワード (32 ビット) でアラインされた数値符号化で、複数の数値符号化を使い分ける
- 4 バイト (32 ビット) ごとにブロック化して符号化する
- 最上位の 4 ビットをレイアウト (layout) といい、残りの 28 ビットの符号化方法(全9種類)を指定するのに使用する
0: 1つの 28 ビットの数値1: 2つの 14 ビットの数値2: 3つの 9 ビットの数値(+ 1つのスペアビット)3: 4つの 7 ビットの数値4: 5つの 5 ビットの数値(+ 3つのスペアビット)5: 7つの 4 ビットの数値6: 9個の 3 ビットの数値(+ 1つのスペアビット)7: 14個の 2 ビットの数値8: 28個の 1 ビットの数値
- ビットマスクを使って効率的にデコードできる
- Simple-16 は 16 種類の符号化を使うバージョン
- 他にも 64 ビットワードへの拡張など
講義資料
- Index Compression (pdf)
- Postings Compression
参考資料
- IIR chapter 5
- MG sections 3.3-3.4
- Compression of inverted indexes for fast query evaluation (Scholer et al. 2002)
- Inverted index compression using word-aligned binary codes (Anh and Moffat 2005)
- Variable byte codes
- Inverted index compression and query processing with optimized document ordering (Yan et al. 2009)
- Word aligned codes
Information Retrieval and Web Search まとめ(7): 辞書の圧縮
前回は、MapReduce を使った分散インデキシングと、ログマージによる動的インデキシングについて説明した。今回は、インデックス圧縮技術の1つである辞書の圧縮について解説する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の7日目の記事です。
転置インデックスの圧縮
- 一般的な圧縮のメリット
- ディスクスペースの節約
- メモリ内により多くのものを入れられる
- ディスクからメモリへの転送速度を上げられる
- 圧縮済みデータを転送して展開するのは、展開済みデータを読み込むよりも速い
- これから説明する展開アルゴリズムは展開が速いので
- 転置インデックスの圧縮
- 辞書
- メインメモリ内に置きたいので小さくしておきたい
- ポスティングファイル
- 必要なディスクスペースを削減したい
- ディスクからポスティングリストを読み込む時間を減らしたい
- 大規模な検索エンジンは、ポスティングの重要な部分はメインメモリに持っている
- 圧縮するとより多くのポスティングをメモリに置ける
- 辞書
- このあと、様々な情報検索特有の圧縮手法について説明する
タームの統計的性質
- タームの語彙数 = ユニークな単語の数
- 上限を仮定できない(文字が Unicode ならなおさら)
Heap の法則
- Heap の法則 (Heap's law)
M = kT^bM: 語彙数T: コレクション中のトークン総数- 典型的には
30 <= k <= 100かつb ~ 0.5
MとTの両対数プロット (log-log plot) は傾きが約1/2の直線になる- Heap の法則の推定
log M = log k + b log Tという線形の関係- Heap の法則は経験則
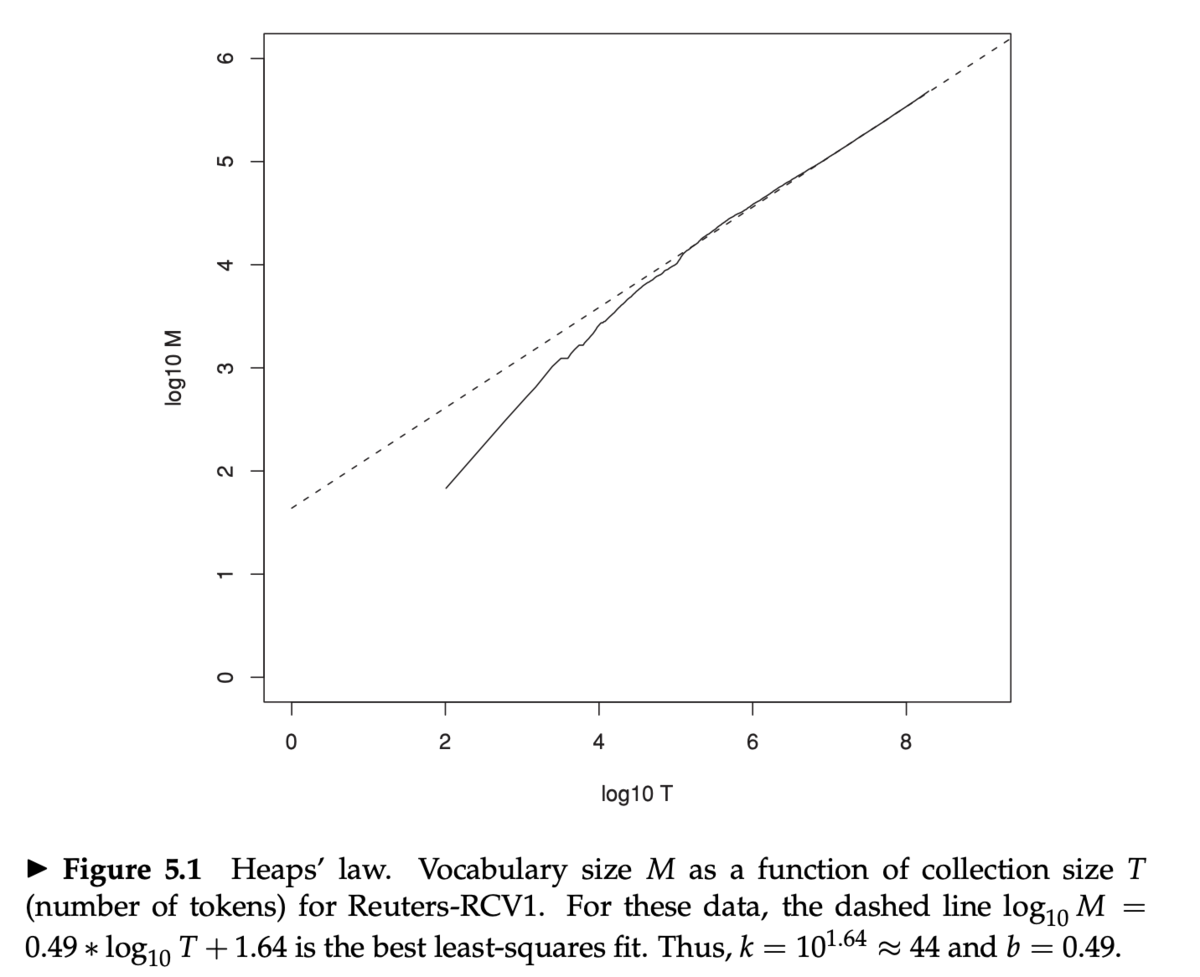
- 点線は Heap の法則によるフィッティングで、
log_10 M = 0.49 log_10 T + 1.64の直線M = 10^1.64 T^0.49k = 10^1.64 ~ 44、b = 0.49
- Reuters-RCV1 ではよくフィットしている
Zipf の法則
- Heap の法則は、コレクション中の語彙数を予測した
- (相対的な)ターム頻度についても議論する
- 自然言語では、いくつかの非常に高頻度な単語と、非常に多いとてもレアな単語とがある
- Zipf の法則 (Zipf's law)
- 「頻度が i 番目に多い単語の頻度は
1/iに比例する」 cf_i ∝ 1/i = K/iK: 正規化の定数cf_i: コレクション頻度(コレクション中のタームt_iの出現回数)
- 「頻度が i 番目に多い単語の頻度は
- 最も頻度(出現回数)の多い単語 (the) の出現回数が
cf_iだとすると- 2番目の単語 (of) は
cf_1 / 2回 - 3番目の単語 (of) は
cf_1 / 3回 - ...
- 2番目の単語 (of) は
cf_i = K/i(Kは正規化の定数)とするとlog cf_i = log K - log ilog cf_iとlog iのあいだに線形の関係がある

辞書の圧縮
- 辞書は検索のたびに使われるのでメモリ上に置きたい
- そのため、辞書の圧縮は非常に重要
固定長配列による辞書
- 固定長の配列で辞書を表現する
- 辞書のナイーブなバージョン
- 40 万タームあった場合、タームあたり 28 バイトなので全体で 11.2 MB 必要
- しかもこれはタームがアルファベットで、かつ最大 20 文字の場合

termカラムは、1文字のタームでも 20 バイト消費する- 英語の単語は平均して ~4.5 文字
- 辞書内の単語は ~8 文字
- しかも、20 文字以上のタームは扱えない
タームリストの圧縮: 文字列としての辞書
- 文字列としての辞書 (dictionary as a string)
- 辞書を(非常に長い)文字列として保存する
- 最大で 40% のスペースを節約できると期待できる
- ターム頻度の保存に 4 バイト
- ポスティングへのポインタに 4 バイト
- タームへのポインタに 3 バイト
- タームの文字列は平均 8 バイト
- 400K ターム * (4 + 4 + 3 + 8) = 7.6 MB
- 固定長配列では 11.2 MB

ブロック化
- タームへのポインタを、
kタームごとに保存する- たとえば
k = 4
- たとえば
- タームの長さを、ターム文字列とターム文字列の間に保存する必要がある(+ 1バイト必要)

- ブロックサイズ
k = 4のとき、ターム4つごとにポインタのために必要なスペースは- ブロック化なし:ポインタごとに 3 バイト必要だったので 3 * 4 = 12 バイト
- ブロック化あり:3 + 4 = 7 バイト
- 辞書全体では 7.6 MB --> 7.1 MB
kを大きくするとさらに小さくなる
辞書検索
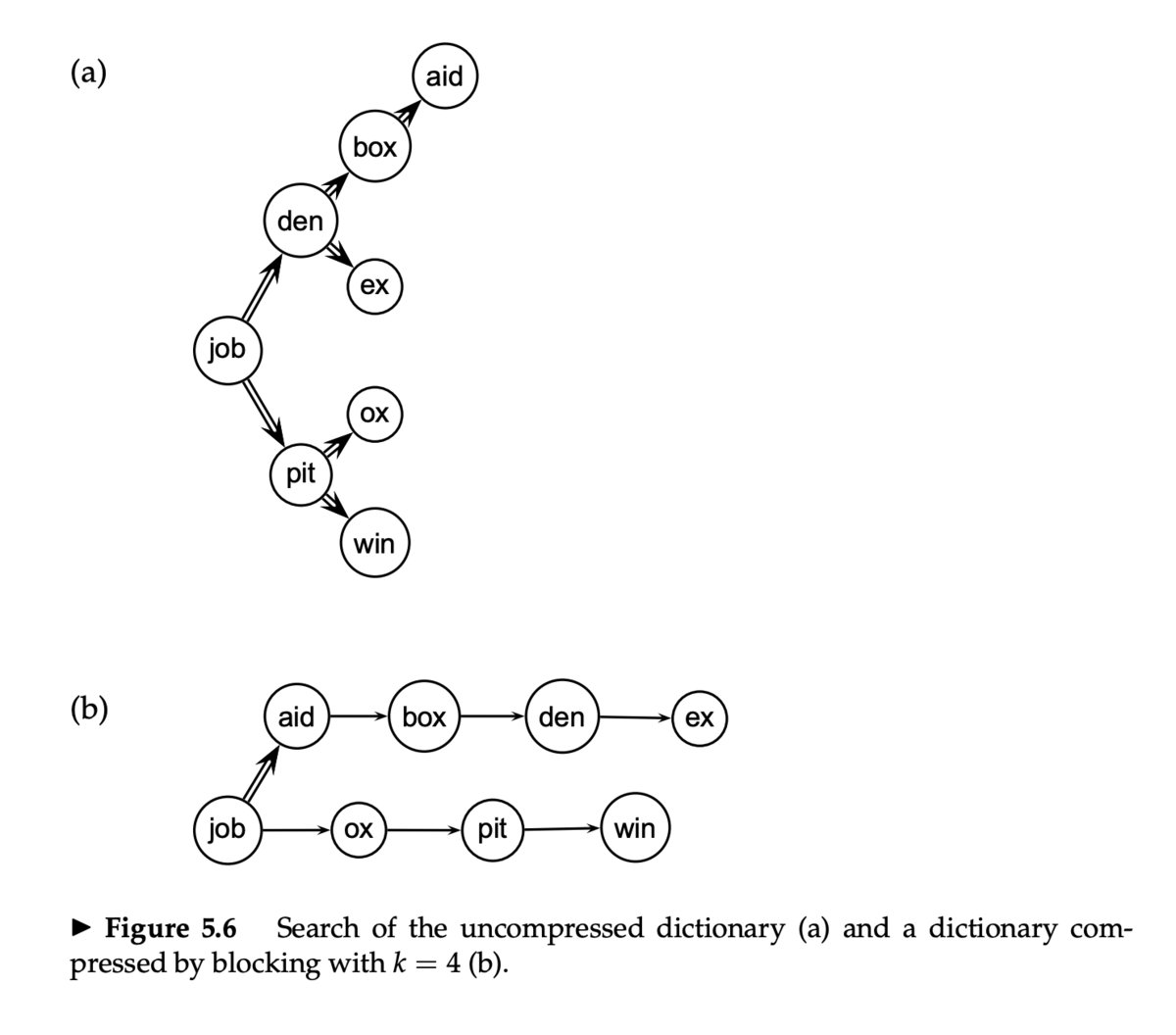
- ブロック化なしでの辞書検索 (Figure 5.6a)
- 各タームが同じ確率で検索されると仮定すると(実際には異なるが)、平均的な比較回数は
(1 + 2 * 2 + 4 * 3 + 4) / 8 ~ 2.6
- 各タームが同じ確率で検索されると仮定すると(実際には異なるが)、平均的な比較回数は
- ブロック化ありでの辞書検索 (Figure 5.6b)
- 二分探索は 4 タームのブロックごとになる
- そのあと、ブロック内を線形探索
- 比較回数は平均で
(1 + 2 * 2 + 2 * 3 + 2 * 4 + 5) / 8 = 3
- 二分探索は 4 タームのブロックごとになる
Front coding
- ソート済みの単語は長い共通接頭辞をもつことが多い
- 差分のみを保存する

- 辞書に "automata", "automate", "automatic", "automation" の4つのタームがある(ブロック化済み)
- "automat" が共通接頭辞
- 共通接頭辞あとには特殊記号
*を置く
- 共通接頭辞あとには特殊記号
- そのあと、差分の文字列と、その長さを置く
- そのあとにはそれぞれ特殊記号
⋄を置く
- そのあとにはそれぞれ特殊記号
辞書圧縮の効果

- ブロック化と Front coding による圧縮で 5.9 MB まで小さくなる
講義資料
- Index Compression (pdf)
- Dictionary Compression
参考資料
- IIR chapter 5
- MG sections 3.3-3.4
Information Retrieval and Web Search まとめ(6): インデックス構築(2)
前回は、1つのマシンを使ったインデックス構築アルゴリズムである BSBI (Blocked sort-based indexing) と SPIMI (Single-pass in-memory indexing) を紹介した。今回は、分散インデキシングと動的インデキシングについて説明する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の6日目の記事です。
分散インデキシング
- Web スケールのインデキシングでは、分散コンピューティングクラスタが必要
- Web 検索のデータセンター(Google, Bing, Baidu)では主にコモディティマシンを使用
- データセンターは世界中に分散している
- Google では 〜100 万台のサーバ、 300 万プロセッサ・コアを使っていると予想されている(Gartner 2007)
- 1000 ノードの非フォールトトレラントシステムで、各ノードの稼働率が 99.9% のとき、システム全体の稼働率は何%か?
- 答え:37%。つまり 63% の時間は1つかそれ以上のサーバーはダウンしている
- 演習:100 万台のサーバーがある場合、1分間のあいだに障害が発生するサーバーの台数は?
- 分散インデキシング
- マスター (master) マシンが、インデキシングジョブを指揮する
- 「安全」であると考えられるように維持する
- インデキシングを複数の並列タスクへと分割する
- マスターマシンは、タスクのプールからそれぞれのタスクをアイドル状態のマシンに割り当てる
- マスター (master) マシンが、インデキシングジョブを指揮する
並列タスク
- 2種類の並列タスクを使う
- パーサー (parsers): Map フェーズ
- インバーター (inverters): Reduce フェーズ
- 入力となる文書コレクションを、スプリット (split) に分割する
- スプリットは、文書集合のサブセット(BSBI/SPIMI におけるブロックに対応する)

パーサー
- マスターはアイドル状態のパーサーマシンにスプリットを割り当てる
- パーサーは文書を1つずつ読み込み、
(termID, docID)ペアを出力する - パーサーはそのペアを j 個のパーティションに書き込む
- 各パーティションはタームの最初の文字の範囲で分けられる
- 例:
a-fg-pq-zの範囲に分かれている場合、j = 3
インバーター
インデックス構築
- インデックス構築はただ一つのフェーズとして説明していた
- もう1つのフェーズが考えられる
- ターム分割インデックス (term-partitioned index) を、文書分割インデックス (document-partitioned index) に変換するフェーズ
- term-partitioned: 1台のマシンはタームの1つの範囲を扱う
- document-partitioned: 1台のマシンは文書の1つの範囲を扱う
- ターム分割インデックス (term-partitioned index) を、文書分割インデックス (document-partitioned index) に変換するフェーズ
- このあと Web のパートで議論するように、ほとんどの検索エンジンは文書分割 (document-partitioned) インデックスを使っている
MapReduce
- 以上のインデックス構築アルゴリズムは、 MapReduce の1つの具体例である
- MapReduce (Dean and Ghemawat (2004)) はロバストで、概念的にはシンプルな分散コンピューティングフレームワーク
- 分散部分のコード以外は
- 彼らは Google インデキシングシステム (ca. 2002) を、それぞれが MapReduce で実装されている複数のフェーズからできていると書いている

動的インデキシング
- ここまで、コレクションは静的なものであると仮定していた
- 時間経過に伴って、文書が入ってきて、インデックスに挿入する必要がある
- 文書は削除されたり更新されたりする
- つまり、辞書やポスティングリストは更新できなければならない
- ポスティングリストを更新
- 新しいタームを辞書に追加
シンプルなアプローチ
- 大きなメインインデックスを管理する
- 新しい文書は小さい補助インデックスに入れる
- 検索するときには両方のインデックスから検索し、結果をマージする
- 削除
- 削除された文書のビットベクトルを管理する
- このビットベクトルを使って、検索結果から削除済み文書をフィルタする
- 定期的に補助インデックスをメインインデックスにマージする
- 問題点
- 頻繁にマージが起こる
- マージ中はパフォーマンスが低下する
- 頻繁にマージが起こる
- 対策として、ポスティングリストごとにファイルを分けておくと効率的にマージできる
- マージはポスティングリストに追記するだけ
- しかし、大量のファイルができるので OS にとっては負担になる
- この講義ではインデックスは1つの大きなファルであると仮定
- 実際には、その中間のアプローチをとる
- ポスティングリストは複数に分割
- 長さ1のポスティングリストは1つのファイルに集める
- など
ログマージ
- ログマージ (logarithmic merge) は、複数のインデックスを管理するアプローチで、それぞれのインデックスは、以前のものの2倍の大きさになる
- 各インデックスはあるサイズ
nの2のべき乗の大きさになる n,2n,4n,8n, ...
- 各インデックスはあるサイズ
- 最も小さいインデックス
Z0をメモリ上にもつ - 大きいインデックス (
l0,l1, ...) はディスク上に置く l0がなかったら、Z0のサイズがnを超えたらl0としてディスクに書き出すl0がすでにあったら、l0とマージしてZ1とする
l1がなかったら、Z1をl1としてディスクに書き出すl1がすでにあったら、l1とマージしてZ2とする

- シンプルなアプローチ(メインインデックス+補助インデックス)では、マージの回数は
T/nTはポスティングの総数nは補助インデックスのサイズ- インデックス構築の最悪時間計算量は
O(T^2/n)- 各ポスティングに対して
T/n回のマージが起こった場合
- 各ポスティングに対して
- ログマージでは、各ポスティングがマージされる回数は最大でも
O(log (T/n))- しかし、クエリ処理は
O(log (T/n))個のインデックスに対して行ってマージしないといけない- シンプルなアプローチでは
O(1)だった(メインインデックス+補助インデックスだけ)
- シンプルなアプローチでは
- しかし、クエリ処理は
- さらに、コレクション横断の統計量を管理するのが大変
- たとえばスペル訂正とか
- これらは後で見るように、ランキング計算に必要
検索エンジンでの動的インデキシング
- すべての大きな検索エンジンは動的インデキシングをやっている
- インデックスが頻繁に更新されている
- インデックスは定期的にスクラッチから再構築してることがよくある
- クエリ処理を新しいインデックスに向け、古いインデックスは削除する
講義資料
- Index Construction (pdf)
- Distributed indexing
- Dynamic indexing
参考資料
- IIR chapter 4
- MG chapter 5
- MapReduce の元論文: Dean and Ghemawat (2004)
- Earlybird: Busch et al, ICDE 2012
Information Retrieval and Web Search まとめ(5): インデックス構築(1)
前回はフレーズクエリと位置インデックスについて説明した。今回は、基本的なインデックス構築と、外部メモリ(=ストレージ)を使ったインデキシングについて紹介する。
この記事は Information Retrieval and Web Search Advent Calendar 2020 の5日目の記事です。
基本的なインデックス構築の流れ
2日目の記事(転置インデックス)では、簡単な転置インデックスの構築方法を解説した。だが、メインメモリのサイズには上限がある。その上でどのように大きなインデックスを構築すればいいだろうか。
- (1) すべての文書をパースし、単語を抽出し、文書 ID (docID) とともに保存する
Term docID I 1 did 1 enact 1 julius 1 caesar 1 I 1 ... brutus 1 killed 1 me 1 so 2 let 2 it 2 be 2 with 2 caesar 2 ... was 2 ambitious 2
- (2) すべての文書のパースが終わったら、転置ファイルをタームの辞書順でソートする
- 以後、このソートステップに注目する
Term docID ambitious 2 be 2 brutus 1 brutus 2 capitol 1 caesar 1 caesar 2 caesar 2 did 1 enact 1 ... was 1 was 2 with 2
Reuters-RCV1 コレクション
- Reuters のニュース記事1年分(1995-1996)のコレクションを使う
- それほど大規模なわけではないが、公開データセットとしてはそれなりのサイズ

- Reuters-RCV1 の統計情報のサマリは以下の通り

ソートベースのインデックス構築
- インデックスの構築中は、文書を1つずつパースしていく
- 最後の文書までパースしないと最終的なポスティングリストは確定できない
- 単語ごとに
(termID, docID)のペアを保存しなければならない- それぞれ 4 バイトと仮定(合計 8 バイト)
- Reuters-RCV1 では全トークン数が 100M くらいあるので、それだけで 800 MB のスペースが必要
- 今日のコンピュータでは実行可能だが、典型的なコレクションはもっと大きい
- 例: New York Times は 150 年分以上のニュース記事のインデックスを提供している
- なので、中間結果をディスクに保存する必要がある
- インメモリのインデックス構築ではスケールしない
ハードウェアの基本
- 検索システムに使われるサーバは通常、数〜数十GBのメインメモリをもつ
- ディスクサイズはその数十〜数百倍
- メインメモリへのアクセスは、ディスクに比べてはるかに速い
- ディスクシークの間はデータが転送できない
- つまり、小さなデータをたくさん転送するより、1つの大きなデータを転送したほうが速い
- ディスクIOはブロックベース
- ブロックサイズは 8 KB ~ 256 KB
- そのため、ディスク上でソートするのは非現実的
- 大量のディスクシークが発生するため、とても遅い
- 外部メモリを使った別のソートアルゴリズムが必要

BSBI (Blocked sort-based indexing)
- BSBI (Blocked sort-based indexing) は、外部メモリを使ったインデキシング方法
- 各レコード
(termID, docID)(8バイト) を 1000 万個(10 M)くらいまでのまとまり(ブロック)に分ける- 全レコード数は約 1 億個 (100 M) なので、10 ブロックに分割される
- 基本的なアイデア
- ブロックごとにポスティングを集めてソートし、ディスクに書き出す
- そのあと、それらのブロックをソート順を保ちながらマージする
BSBI のアルゴリズム

- ブロックを読み込み、その中のレコードをソートし、ディスクに書き出す
- クイックソートの時間計算量は
O(N ln N)(N= 10 M)
- クイックソートの時間計算量は
- 10 ブロックを2つずつマージしていく
- (1, 2) (3, 4) (5, 6) (7, 8) (9, 10) というふうにマージ
- 次は (1, 2) と (3, 4) をマージ……というふうに続ける
- マージツリーは log2 10 = 4 階層になる
- マージした結果はまたディスクに書き出す

- しかし、すべてのブロックを同時に読み込みながらマージするマルチウェイマージ (multi-way merge) のほうが効率的
- すべてのブロックのファイルを同時に開く (open)
- それぞれのブロックごとに読み込みバッファを作って管理
- 各イテレーションでは、最も小さい termID を1つ選ぶ
- この termID は優先度付きキューを使って選択する
- 選んだ termID に関するすべてのポスティングリストをマージして、出力ファイルに書き出す
- すべてのブロックのファイルを同時に開く (open)
- 読み込み・書き出しのためのバッファのサイズを適切にしていれば、ディスクシークで死ぬことはない
- 残っている問題
- 辞書はメインメモリに収まることを仮定している
- タームから termID にマッピングするために、動的に追加できる辞書 (term-termID mapping) が必要
SPIMI (Single-pass in-memory indexing)
- SPIMI (Single-pass in-memory indexing) は BSBI よりさらにスケーラブルなインデックス構築アルゴリズム
- キーとなるアイデア
- ブロックごとに別々の辞書を生成する
- term-termID mapping が不要になる
- ソートしない
- ポスティングリストのエントリは出現した順に集めていく
- ブロックごとに別々の辞書を生成する
- これにより、ブロックごとに完全な転置インデックスが生成される
- 別々に生成されたインデックスは1つの大きなインデックスにマージできる
SPIMI のアルゴリズム

- SPIMI は BSBI と違ってポスティングリストにポスティングが直接追加される (L10)
- BSBI では最初にすべての termID-docID ペアを集めてからソートしていた
- そのため、 SPIMI ではポスティングリストは動的に拡張される
- ソートが不要になるので高速
- ポスティングリストが属しているタームを管理しなくてよいのでメモリ消費量が少ない
- 圧縮を使うことで SPIMI をさらに効率的にできる
- タームの圧縮
- ポスティングの圧縮
- 圧縮については次回以降で扱う
- IIR chapter 5
講義資料
- Index Construction (pdf)
- Basic inverted index construction
- External memory indexing